Java基础
基础概念
1. java的特点
主要有三点:1)平台无关性|跨平台性 2)面向对象 3)内存管理(垃圾回收)
2. 优势和劣势
一句非常经典的话能够体现java的优势:一次编译,处处运行,当然除了平台无关性,java的优势还有面向对象、内存管理、juc等等,但目前来看,其他语言也都有像是多线程、面向对象的特性,在我看来,java最大的优势就是其生态强大。
Java 的主要缺点在于其性能通常不如 C++,原因包括:代码需先编译为字节码,再由 JVM 通过解释或 JIT 编译为机器码,引入了额外开销;
其次:Java 程序启动时需要先加载 JVM,然后加载类、初始化类、运行主函数。在微服务或短生命周期任务中,这成为明显劣势。
最后:面向对象过于严格,有时候写简单程序反而麻烦,虽然Java8引入了函数式编程,但不如其他语言自然。
3. 为什么是跨平台的
Java 能支持跨平台,主要依赖于 JVM:也就是只有不同的平台都有jvm,那么java代码就能在不同的平台上运行。
这是因为java使用jvm将平台的差异化给抹除了,也就是不同的平台安装的jvm不同,只是解释出来的机器码不同,但对于字节码文件这样的不同是无感的,在因此,java代码就是跨平台的。
4. JVM、JDK、JRE三者关系
-
JVM是Java虚拟机,是Java程序运行的环境。它负责将Java字节码(由Java编译器生成)解释或编译成机器码,并执行程序。JVM提供了内存管理、垃圾回收、安全性等功能,使得Java程序具备跨平台性。
-
JDK是Java开发工具包,是开发Java程序所需的工具集合。它包含了JVM、编译器(javac)、调试器(jdb)等开发工具,以及一系列的类库(如Java标准库和开发工具库)。JDK提供了开发、编译、调试和运行Java程序所需的全部工具和环境。
-
JRE是Java运行时环境,是Java程序运行所需的最小环境。它包含了JVM和一组Java类库,用于支持Java程序的执行。JRE不包含开发工具,只提供Java程序运行所需的运行环境。
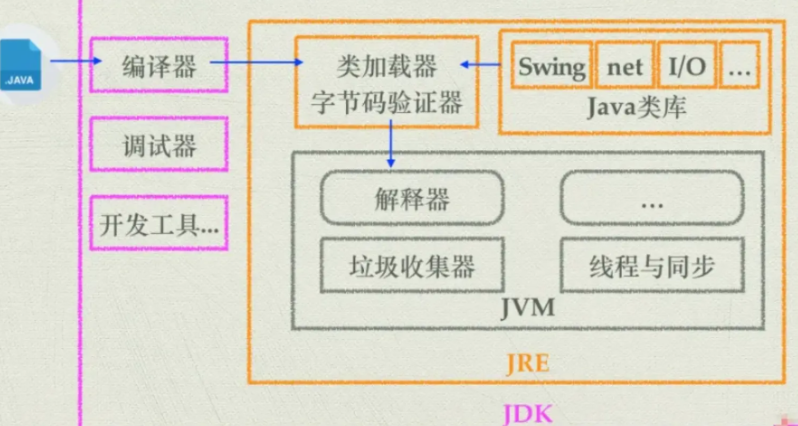
5. JVM 是什么⭐️
JVM 是 java 虚拟机,主要工作是将这些字节码动态地解释或通过 JIT(即时编译器) 编译为当前操作系统和 CPU 能识别的本地机器指令并执行。此外,JVM 还包括了内存管理、安全校验等全套服务。
JVM屏蔽了与操作系统平台相关的信息,使得Java程序只需要生成在Java虚拟机上运行的目标代码(字节码),就可在多种平台上不加修改的运行,这也是Java能够“一次编译,到处运行的”原因。
6.编译型与解释型语言
-
编译型语言:在程序执行之前,整个源代码会被编译成机器码或者字节码,生成可执行文件。执行时直接运行编译后的代码,速度快,但跨平台性较差。
-
解释型语言:在程序执行时,逐行解释执行源代码,不生成独立的可执行文件。通常由解释器动态解释并执行代码,跨平台性好,但执行速度相对较慢。
-
典型的编译型语言如C、C++,典型的解释型语言如Python、JavaScript。
7. 为什么java解释和编译都有⭐️⭐️
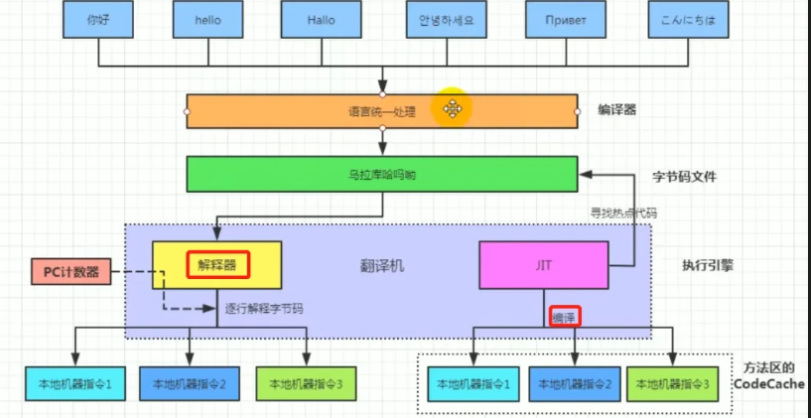
- java 源代码被java编译器编译为字节码文件,此外,jit会将热点代码(被频繁使用的方法)动态编译为本地机器码并缓存起来供后续重复使用,这都体现了java的编译性
- jvm 会将字节码文件解释为机器指令并执行,这体现了java的解释性
所以Java既是编译型也是解释性语言,默认采用的是解释器和编译器混合的模式。
- 字节码(Bytecode):是Java源代码编译后生成的中间代码,不是机器码,可以在不同平台上运行。
- 解释执行:由JVM中的解释器逐条读取字节码并翻译成本地机器指令执行,速度较慢。
- JIT(Just-In-Time Compiler):即时编译器,在程序运行过程中,对热点代码(频繁执行的方法)进行动态编译,将字节码直接编译为本地机器码,并缓存起来供后续重复使用。
8. 值传递和引用传递⭐️⭐️
在 Java 中,所有参数传递都是值传递,不存在真正的“引用传递”。核心区别在于:
| 类型 | 传递内容 | 是否影响原值 |
|---|---|---|
| 基本类型 | 值的副本 | ❌ 不影响 |
| 引用类型 | 引用的副本 | ✅ 可修改对象内容,❌ 不可改变原引用指向 |
x. JIT
Java 源代码首先被编译成一种中间形式——字节码(bytecode),而不是直接变成机器码。字节码不能被 CPU 直接执行,必须由 JVM 来处理。
最初,JVM 是通过 解释器(interpreter) 逐行解释字节码来运行程序的,这种方式简单但很慢。
为了解决这个问题,JIT 编译器被引入:它会在程序运行时,把频繁执行的字节码(热点代码)动态编译成高效的本地机器码,并缓存起来供后续直接使用。
数据类型
Java 支持的数据类型分为两类,分别为基本数据类型和引用数据类型,基本数据类型也就是变量本身就存储变量值,而引用数据类型存的是变量所在内存地址
1. java 的八种基本数据类型
基本数据类型分为:
-
数值型:byte, short, int, long, float, double
-
字符型:char (2个字节)
-
布尔型:boolean
注意点: - Java中基本数据类型的字节数:1字节(byte、boolean)、2字节(short、char)、4字节(int、float)、8字节(long、double)。
-
浮点数的默认类型为double(声明一个常量为float,则必须在末尾加上f或F)。
-
整数的默认类型是int(声明long类型要在末尾加上l或L)。
-
八种基本数据类型的包装类:除了char的是Character、int类型的是Integer,其他都是首字母大写。
-
char类型是无符号的,不能为负,所以是0开始的。
2. int 和 long 占多少位,多少个字节
int 类型是 32 位(bit),占 4 个字节(byte),是有符号整数类型,其取值范围是从 -2^31 到 2^31-1。例如,在一个简单的计算器程序中,如果使用 int 类型来存储计数值,它可以表示的最大正数是 2,147,483,647。如果计数值超过这个范围,就会发生溢出,导致结果不符合预期。
long 类型是 64 位,占 8 个字节,long 类型也是有符号整数类型,它的取值范围是从 -2^63 到 2^63-1,在处理较大的整数值时,当 int 类型的取值范围不够,就需要使用 long 类型。例如,在一个文件传输程序中,文件的大小可能会很大,使用 int 类型可能无法准确表示,而 long 类型就可以很好地处理这种情况。
3. long 和 int 可以互转吗
可以的,Java中的 long 和 int 可以相互转换。由于 long 类型的范围比 int 类型大,因此将 int 转换为 long 是安全的,而将 long 转换为 int 可能会导致数据丢失或溢出。
int num = 100;
long bigNum = num; // int -> long 小转大,安全,自动转化
int samllNum = (int)bigNum // long -> int 大转小,不安全,需要强制转换
4. 数据类型转换方式
-
自动类型转换(隐式转换):当目标类型的范围大于源类型时,Java会自动将源类型转换为目标类型,不需要显式的类型转换。例如:将
int转换为long、将float转换为double等。 -
强制类型转换(显式转换):当目标类型的范围小于源类型时,需要使用强制类型转换将源类型转换为目标类型。这可能导致数据丢失或溢出。例如:将
long转换为int、将double转换为int等。语法为:目标类型 变量名 = (目标类型) 源类型。 -
字符串转换:Java提供了将字符串表示的数据转换为其他类型数据的方法。例如:将字符串转换为整型,可以使用
Integer.parseInt()方法;将字符串转换为浮点型double,可以使用Double.parseDouble()方法等。 -
数值之间的转换:Java提供了一些数值间转换的方法,如整型转换为字符型、字符型转换为整型等。这些转换方式可以通过相应的包装类来实现,例如
Character类、Integer类等提供了相应的转换方法。
5. 数据类型转换会出现什么问题呢
-
当目标类型比原类型小的话,此时可能出现溢出或者数据丢失的现象,比如 long -> int
-
其次,在浮点数进行转换的时候,可能会出现精度丢失的问题。
-
对象引用转换的问题:子类强转为父类是向上转型,是安全的;而父类强转为子类才可能出错(需确保实际对象是该子类实例),但这属于引用类型转换,不属于基本数据类型转换范畴。
6. 为什么用 bigDecimal 而不是double⭐️
因为 double 会出现精度丢失问题,由于它执行的是二进制浮点运算,也就是说,double 只能精确表示能被 \(\sum_1^n{2^{-n}}\) 的组合,而无法被精确组合出来的只能近似表示。
由于这一特性,double 在一些进度要求极高的场景下就不适用了,比如电商平台的购物场景,总不能用户看到商品价格是10元,他的余额也刚好又有10元,而如果是 double,那么很可能会出现用户无法购买商品的场景,因为商品的10可能是10.00000001,而用户的10可能是9.999999999。
7. 装箱和拆箱是什么⭐️
装箱和拆箱描述的是基本数据类型与它对应的包装数据类型的过程。
当我们用一个包装类型去接收对应的基本数据类型的话,java会帮我们自动的将它转换为该包装类,这就是装箱。
而拆箱就是用基本数据类型去接收其对应的包装类。在赋值时、给方法传参时以及返回值时,都有可能进行自动的装箱和拆箱
弊端:在循环中频繁的装箱拆箱可能会导致性能问题
8. java为什么要有基本数据类型的包装类
(1)Java 是一门面向对象的语言,而基本数据类型(如 int、double、boolean 等)不是对象,不能直接参与面向对象的操作(比如继承、多态、作为泛型参数等)。包装类(如 Integer、Double、Boolean)将基本类型“包装”成对象,使其具备对象的特性。
(2)其次,java的集合类只能存储对象,不能直接存储基本数据类型。
总之:包装类让基本数据类型具备对象特性,从而能融入 Java 的面向对象体系(尤其是集合、泛型、反射等),同时提供额外工具方法和 null 语义支持。
9. integer 相比 int 有什么特点
(1)integer不是基本数据类型,而是引用数据类型,它能够融入java的面向对象体系中。
(2)在集合中,只能存储 Integer 等包装类,而不能存储基本数据类型
10. 引用和基本数据类型
基本数据类型存储在栈内存(当他们是局部变量的时候),它们直接存储值本身。 而引用数据类型本身存放在栈内存,它们存储的是对象在堆内存的地址。
11. 有了包装类,为什么还要保存基本数据类型呢
首先,包装类只是为了让基本数据类型具备对象的特征,从而融入java的面向对象体系中,比如作为泛型参数,存放到集合中,但在平时的数值计算中,我们总不能用两个对象去计算吧,这样多此一举,效率还低,而基本数据类型就可以直接进行数值运算。
12. Integer 的缓存机制⭐️⭐️
为了提高性能和减少内存开销,Java 对 Integer(以及其他部分包装类如 Byte、Short、Long、Character)在一定数值范围内实现了对象缓存机制。
- 默认缓存范围:
-128到127(包含两端)(\(-2^7, 2^7 - 1\)) - 当使用
Integer.valueOf(int)或自动装箱创建Integer对象时,如果值落在该范围内,不会新建对象,而是直接返回缓存中的已有对象。 - 超出此范围才会创建新对象。
📌 注意:直接用 new Integer(100) 会绕过缓存,始终创建新对象!
13. 为什么设计这个缓存
-
小整数使用频率极高(如循环计数、状态码等),缓存可避免重复创建相同对象。
-
节省堆内存,减少 GC 压力。
-
提升性能:复用对象比频繁创建/销毁更快。
面向对象
1. 怎么理解面向对象呢?⭐️⭐️⭐️
面向对象(Object-Oriented Programming, OOP)是一种编程思想,它将现实世界中的事物抽象为“对象”。每个对象都有自己的属性和行为。
面向对象以“对象”为中心,通过对象之间的交互来完成程序功能,相比传统的面向过程,具有可维护性、可扩展性更强,也更加规范。
总结: 面向对象就是把现实事物抽象成对象,通过三大特性——封装(保护数据)、继承(复用代码)、多态(灵活扩展)——来构建灵活、可维护的程序。
2. 封装、继承、多态⭐️
(1)封装:将对象的属性和行为封装在一起,隐藏内部实现细节,只对外提供接口。
(2)继承:允许一个类继承另一个类的属性和方法,从而实现代码复用。
(3)多态:同一个方法,在不同实现类或者对象中表现出不同行为。
3. 多态体现在那些方面
-
方法重载
-
方法重写
-
接口与实现
4. 多态解决了什么问题⭐️⭐️
多态通过“抽象”实现了“解耦”,让程序能够对“扩展”开放,对“修改”关闭(即 OCP 开闭原则)。
没有多态时:每增加一个新功能(比如新加一种支付方式),你都得去修改原有的业务代码,增加一个 else if。这不仅麻烦,还容易改坏原来的逻辑。
有了多态后:你只需要定义一个 Payment 接口。增加新支付方式时,直接写个新实现类即可。原有的调用逻辑(父类引用调用方法)一行代码都不用动。
补充:“多态在底层是怎么知道该调用哪个子类方法的?”
“在 JVM 层面,这是通过动态绑定(Dynamic Binding)实现的。对于非私有、非静态、非 final 的方法,JVM 会在运行时查找对象的虚方法表(vtable),根据实际指向的堆内存对象类型来确定方法入口,而不是根据声明的变量类型。”
5. 面向对象的设计原则
核心目的:写出高内聚,低耦合,易维护,可拓展的代码
总结:高内聚、低耦合、多用接口,少用实现类、类要专注、拓展不改源码
| 原则 | 核心思想 | 简单解释 |
|---|---|---|
| 单一职责原则(SRP) | 一个类只做一件事 | 如:员工类只管员工信息,不负责工资计算 |
| 开放封闭原则(OCP) | 对扩展开放,对修改关闭 | 通过接口/抽象类扩展功能,不改原有代码 |
| 里氏替换原则(LSP) | 子类可以替换父类而不影响程序正确性 | 正方形不能直接继承矩形(因为高度宽度必须相等,破坏了“改变宽高”的行为一致性) |
| 接口隔离原则(ISP) | 客户端不应依赖不需要的接口 | 接口要小而精,避免“胖接口” |
| 依赖倒置原则(DIP) | 高层模块不依赖底层细节,依赖抽象 | 用接口编程,而不是具体实现 |
| 最少知识原则(LoD) | 一个对象应尽量少了解其他对象 | 只和“朋友”交互,避免过度耦合 |
6. 重写和重载⭐️
重载是指在同一个类中,可以有多个同名的方法,他们具有不同的参数列表(参数个数、参数顺序,参数类型),编译器根据调用时的参数来决定执行哪个方法。
重写是指子类可以重新定义父类中的方法,需要注意,重载必须保证 方法名,方法参数,返回类型相同,修饰符可以不同。(子类的访问修饰符不能比父类更严格(即不能缩小访问权限),但可以更宽松。)
| 父类修饰符 | 子类允许的修饰符 |
|---|---|
public |
只能是 public |
protected |
protected 或 public |
| 默认(包私有) | 默认、protected、public |
private |
不能重写(因为不可见) |
final方法不能被重写static方法不能被重写(只能隐藏)abstract方法必须被重写(除非子类也是抽象类)
7. 抽象类和普通类的区别⭐️
- 抽象类不能被实例化,只能被继承
- 普通类中的方法可以有具体的实现,而抽象类中的方法可以有实现,也可以没有实现。
8. 抽象类和接口的描述以及区别⭐️
抽象类用来描述多个类的共同属性和行为,可以有成员变量、构造器、具体方法。它适用于有很明显的继承关系的场景。
接口用来定义一组行为的规范,接口之间的继承是多继承的,也就是一个接口可以同时继承多个父接口。在 java8 接口只能由常量和抽象方法,在java8之后可以有默认方法和静态方法。Java 9 起:还支持 private 方法(用于辅助 default/static 方法)
9. final 修饰符⭐️⭐️
final 是 Java 中的一个关键字,表示“不可变”或“不可继承/重写”,可用于类、方法、变量,作用如下:
| 修饰目标 | 作用 | 说明 |
|---|---|---|
| 类 | 该类不能被继承 | 如 String、Integer 都是 final 类 |
| 方法 | 该方法不能被子类重写(Override) | 常用于防止核心逻辑被篡改 |
| 变量 | 该变量只能赋值一次(即常量) | - 基本类型:值不可变 - 引用类型:引用地址不可变(但对象内部状态可变) |
10. 抽象类能加 final 修饰吗
当然不能,抽象类本身的作用就是被其他类继承,而final修饰的类是不能被任何类继承的。
补充 String 为什么要被 final 修饰?
(1)为了线程安全:因为 String 是不可变的,所以它是天然线程安全的。
(2)支持字符串常量池(String Pool):Java 为了节省内存,会将字符串字面量存放在“字符串常量池”中。如果两个 String 变量的值相同,它们会指向内存中的同一个地址。假设 String 是可变的,如果线程 A 修改了字符串的值,那么所有指向该地址的变量(比如线程 B 里的变量)都会跟着被改变。这会直接导致数据错乱,常量池也就失去了意义。
(3)String 被广泛用于 Java 的各种核心底层参数。不可变性能防止这些关键参数在运行时被恶意篡改。
11. 接口中可以定义那些方法⭐️
抽象方法是接口的核心,所有实现接口的类都必须重写这些方法,抽象方法默认是 public 和 abstract, 在接口中可以省略。
默认方法是在 java 8 中引入的,允许接口提供具体实现,实现类可以选择性的重写默认方法
静态方法也是在 Java 8 中引入的,他们属于接口本身,可以通过接口名直接调用。
私有方法是在 java 9 引入的,该方法存在的意义就是辅助默认方法以及静态方法,实现类是不能访问这些方法的。
public interface Animal(){
void makesound();
static void staticMethod(){
privateMethod();
}
private void privateMethod(){
pass;
}
}
12. 抽象类可以被实例化吗
不能!抽象类本身不能被直接实例化。抽象类的目的是作为基类模板,供其他类继承和实现。
为什么不能进行实例化呢? 因为抽象类中可能含有未实现的方法,如果允许创建对象,那么调用这些方法时程序就不知道该做什么。
那抽象类可以有构造器吗? ✅ 可以! 抽象类可以有构造器。 虽然不能直接 new 抽象类,但当子类实例化时,会自动调用父类的构造器进行初始化。
13. 接口可以包含构造方法吗?
不可以,在接口写构造方法会报错:interfaces cannot have constructors, 因为接口不会有自己的实例,所以不需要有构造方法。
为什么呢不能有呢? 因为构造方法就是初始化 class 的属性和方法,在 new 的一瞬间自动调用,而 java 的接口不能 new 出来,自然就不需要构造方法。
14. 为什么子类初始化都需要先调用父类的构造器呢?
因为子类继承了父类的字段和方法,必须先确保父类部分被正确初始化,才能安全使用。
“子类对象包含了父类的所有非私有成员,为了保证这些成员被正确初始化,Java 要求子类构造器必须(显式或隐式)调用父类构造器——这是面向对象‘完整性’和‘安全性’的基本保障。”
15. java 中的静态变量和静态方法⭐️
静态(static)成员属于类本身,而不是类的实例(对象)。它们在内存中只有一份,被所有实例共享。
1、静态变量
所有实例共用同一个静态变量。
2、静态方法
静态方法是在类中使用 static 关键字声明的方法。与静态变量一样,静态方法是属于类的,在内存在只有一份,所有实例共享改静态方法。
- 无实例依赖:可以在没有创建对象的情况下调用。
- 不能访问非静态成员:不能直接访问实例变量或实例方法(因为没有“this”上下文)。
- 可访问静态成员:可以直接调用其他静态变量/方法。
- 不能被重写(Override):但可以被隐藏(Hide),不是多态的一部分。
使用场景
静态变量用来在所有实例间共享数据。
静态方法常作为工具方法(如 Math.max())、工厂方法、获取类级别信息
16. 什么是内部类
内部类就是定义在另一个类内部的类。它就是外部类的一个属性,也可以被 private, public 等修饰符修饰。
- 内部类是外部类的成员,可以像字段、方法一样被访问控制修饰符(
private、protected等)修饰。 - 它能访问外部类的所有成员(包括私有成员)。
- 编译后会生成独立的
.class文件,命名格式为:外部类$内部类.class
下面就是一个非静态内部类的定义
public class Outer {
private String msg = "这是外部类的成员属性";
// 非静态内部类
public class Inner{
public void show(){
System.out.println(msg);
}
}
// 静态内部类
public static class StaticInner{
public void show(){
System.out.println("这是静态内部类");
}
}
}
17. 静态内部类和非静态内部类有什么区别
非静态内部类的创建依赖于外部类的实例,而静态内部类不依赖于外部类的实例
// 非静态内部类的实例化
@Test
public void test01(){
Outer.Inner inner = new Outer().new Inner();
inner.show();
}
// 静态内部类的实例化
@Test
public void Test02(){
Outer.StaticInner staticInner = new Outer.StaticInner();
}
非静态内部类可以访问外部类的所有属性和方法,包括私有的,而静态内部类只能访问外部类的静态成员。
非静态内部类不能定义静态成员,而静态内部类可以。
非静态内部类在外部类实际化后才能实例化,而静态内部类可以独立实例化。
18. 为什么非静态内部类可以访问到外部方法呢?⭐️⭐️
这是因为在初始化非静态内部类的时候必须先初始化外部类,因为非静态内部类是依赖于外部类的,当通过外部类实例去初始化非静态内部类时,编译器会将外部类的引用传递给 Inner 的构造器,然后Inner内部保存了这个引用(this$0),这使得内部类可以通过这个引用访问 Outer 的所有成员,包括私有的。
关键字
1. final 关键字的作用是什么⭐️
final 是 Java 中的一个关键字,表示“不可变”或“不可继承/重写”,可用于类、方法、变量,作用如下:
| 修饰目标 | 作用 | 说明 |
|---|---|---|
| 类 | 该类不能被继承 | 如 String、Integer 都是 final 类 |
| 方法 | 该方法不能被子类重写(Override) | 常用于防止核心逻辑被篡改 |
| 变量 | 该变量只能赋值一次(即常量) | - 基本类型:值不可变 - 引用类型:引用地址不可变(但对象内部状态可变) |
2. static 关键字的作用⭐️
static 是 Java 中一个非常重要的关键字,用于将成员(变量、方法、代码块、内部类)与类本身关联,而不是与类的实例(对象)绑定。
静态变量:被static修饰的变量属于类本身,而非类的某个实例。所有实例都共享同一份静态变量,内存中只存在一份副本。
静态方法:静态方法也属于类,不属于任何实例,因此在静态方法中不能访问非静态成员,因为没有 this 上下文。
修饰代码块:静态代码块在类加载时执行,且只执行一次(优先于对象的构造方法),它主要用来初始化静态变量或者执行类级别的预处理操作。
修饰内部类:静态内部类也是属于类本身的,而非任何一个实例,静态内部类的创建不依赖于外部类的实例,可以直接创建,但它只能访问外部类的静态成员。
深拷贝和浅拷贝
注意点:对象的所有值都存在堆内存,而该对象的引用可以在栈区(局部变量表),也可以在堆区(静态变量)
1. 什么是深拷贝⭐️
深拷贝:不仅复制对象本身,还会递归地复制所有引用类型的字段所指向的对象,直到所有层级都是新对象。
2. 什么是浅拷贝⭐️
浅拷贝:只复制对象本身的字段值,对于引用类型的字段,仅复制其引用(地址),不复制所指向的对象。
浅拷贝会为新对象分配新的内存,并把原对象的所有字段值(包括基本类型的值和引用类型的地址)原样复制过去。因此基本类型天然隔离,引用类型可能共享 —— 这就是“浅”的含义。
3. 它们的区别是什么
| 对比项 | 浅拷贝 | 深拷贝 |
|---|---|---|
| 基本类型字段 | 复制值(独立) | 复制值(独立) |
| 引用类型字段 | 复制引用(共享对象) | 复制对象(全新实例) |
| 内存关系 | 新旧对象共享部分子对象 | 完全独立的对象树 |
| 修改影响 | 可能互相影响 | 互不影响 |
| 性能开销 | 小 | 大(需递归复制) |
4. 实现深拷贝的3种方式⭐️
第一种:当前类以及当前类中的所有引用类型成员全部实现 cloneable 接口并重写 clone() 方法(手动递归克隆),之后再该类下的 clone 方法手动调用其他引用类型成员的 clone 方法来完成深拷贝。
让所有引用类型成员也实现 `Cloneable` 并重写 `clone()`
在外层对象的 `clone()` 中调用它们的 `clone()`
class Address implements Cloneable {
String city;
public Address(String city) { this.city = city; }
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}
}
class Person implements Cloneable {
String name;
Address address;
@Override
protected Object clone() throws CloneNotSupportedException {
Person p = (Person) super.clone();
p.address = (Address) this.address.clone(); // 手动深拷贝引用对象
return p;
}
}
public class CloneTest {
@Test
public void test01() throws CloneNotSupportedException {
Person p1 = new Person("ltb", "上海");
Person p2 = (Person) p1.clone();
System.out.println(p1);
System.out.println(p2);
System.out.println(p1 == p2);
System.out.println(p1.getAddress() == p2.getAddress());
}
}
p1 与 p2 肯定是不同的,因为无论是深拷贝,还是浅拷贝,都会创建一个新的 person 对象,但是p1 与 p2 的 address 就不一定了,浅拷贝就相同,深拷贝就不同。
第二种:序列化 + 反序列化(推荐通用方案):通过将对象序列化为字节流、再从字节流反序列化为对象来实现深拷贝。要求对象及其所有的引用类型字段都实现 Serializable接口。
import java.io.*;
public static <T extends Serializable> T deepCopy(T obj) {
try {
ByteArrayOutputStream bos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(bos);
oos.writeObject(obj);
ByteArrayInputStream bis = new ByteArrayInputStream(bos.toByteArray());
ObjectInputStream ois = new ObjectInputStream(bis);
return (T) ois.readObject();
} catch (Exception e) {
throw new RuntimeException(e);
}
}
| 问题 | 说明 |
|---|---|
必须实现 Serializable |
所有相关类(包括嵌套对象)都必须可序列化,否则抛 NotSerializableException |
transient 字段会被忽略 |
被 transient 修饰的字段不会被序列化,拷贝后为默认值(如 null, 0) |
| 性能开销较大 | 涉及 I/O 操作和反射,比手动 clone 慢 |
| 不能拷贝静态字段 | 静态变量属于类,不属于对象,不会被序列化 |
第三种:手动递归复制:当对象的结构复杂度不高时,我们也可以手写深拷贝,也就是手动的递归复制对象以及其引用类型字段
泛型
1. 什么是泛型⭐️
泛型(Generics)是 Java 提供的一种“参数化类型”机制,它允许类、接口、方法再定义时使用一个或者多个类型参数,这些类型参数在使用时可以被指定为具体的类型。
- 编译期类型安全:防止把错误类型的对象放入容器(如
List<String>不能放Integer) - 消除强制类型转换:不用再写
(String) list.get(0) - 提高代码复用性:一套代码适配多种类型
2. 泛型的上下界⭐️
用于限制泛型参数的类型范围。
| 类型 | 语法 | 含义 | 使用场景 |
|---|---|---|---|
| 上界(Upper Bound) | <T extends 类/接口> |
T 必须是该类型或其子类型 | 定义泛型类/方法时 |
| 下界(Lower Bound) | <? super 类> |
通配符必须是该类型或其父类型 | 方法参数(通配符) |
3. 通配符是什么?⭐️
通配符 ? 是一种特殊的泛型类型,表示“未知类型 / 任意类型”,主要用于方法参数、局部变量等场景,增强 API 的灵活性。
| 通配符 | 含义 | 能读? | 能写? | 典型用途 |
|---|---|---|---|---|
<?> |
未知类型(无界) | ✅(返回 Object) |
❌(只能写 null) |
只读容器 |
<? extends T> |
T 的子类型(上界通配符) | ✅(返回 T) | ❌(不能 add 具体子类) | 生产者(Producer) |
<? super T> |
T 的父类型(下界通配符) | ❌(返回 Object) |
✅(可 add T 及其子类) | 消费者(Consumer) |
<T extends X> —— 用于“定义”泛型
// 定义泛型类:T 必须是 Number 的子类
public class Box<T extends Number> { ... }
// 定义泛型方法
public <T extends Comparable<T>> void sort(List<T> list) { ... }
<? super T> —— 用于“使用”泛型(通配符)
但当你调用一个方法,想表达“这个容器能接受 T 或其父类型的对象”时,你不需要知道具体类型,只需要限制范围。
// 方法参数:list 可以是 List<Integer>, List<Number>, List<Object>
public void addInt(List<? super Integer> list) {
list.add(100); // 安全:100 是 Integer,肯定能放进这些列表
}
- 上界是为了安全读取:你知道元素至少是
X类型,可以调用X的方法。 - 下界是为了安全写入:你知道容器能接受
T,所以可以add(T)。 - 但在定义类时,你需要一个确定的类型变量(如
T)来编写通用逻辑;而? super T表示“某个未知的父类型”,无法在类内部使用(因为你不知道它到底是什么)。
对象
1. java中创建对象的方式有哪些⭐️
(1)使用 new 关键字
在 java 中,最常见,最基础的创建对象的方式就是使用 new 关键字。这种方式简单直接,但属于强耦合,也就是在编译器就绑定了类型。
(2)通过反射Class.newInstance() 或 Constructor.newInstance()
通过反射机制能够动态的创建对象,(也就是在程序运行时去决定创建哪个对象),这种方法不需要在编译时知道具体的类。
(3) 使用 clone 方法
通过实现 Cloneable 接口并重写 clone 方法,可以基于一个现有的对象创建一个新的对象副本。
(4)使用序列化和反序列化
还可以通过对象输出流将当前对象序列化为字节数组,然后再通过对象输入流将字节数据反序列化为一个全新的对象(值与源对象一致)。
(5)使用工厂模式
这是一种设计模式,在该模式下不直接使用 new 关键字,而是通过一个方法来返回对象实例,比如 getInstance, valueOf 都是常见的工厂方法。 该模式能够将对象的创建与使用分离,降低耦合,还可以隐藏创建对象的复杂逻辑。
2. new 出来的对象什么时候回收⭐️⭐️
通过 new 创建的对象,由 Java 的垃圾回收器(GC)自动管理,当对象不再被任何引用可达时,就会被回收,具体的垃圾回收算法在 jvm 有总结。
3. 如何获取私有成员⭐️⭐️
同时,被private修饰的成员变量或者方法是不让其他类直接访问的,这些成员只能在内部被访问。但是可以通过下面两种方式来间接获取私有成员:
1、使用改对象提供的公共访问器方法,也就是 getters。
2、我们还可以通过反射 api 来轻易的获取一个对象的所有成员,包括私有的。只需要通过 Field 提供的 setAccessible api 即可访问私有成员。
@Test
public void test01() throws IllegalAccessException {
Class<? extends Person> person = p.getClass();
for (Field declaredField : person.getDeclaredFields()) {
declaredField.setAccessible(true);
System.out.println(declaredField.get(p));
}
}
反射
1. 什么是反射⭐️
反射(Reflection)是Java 提供的一种在运行时动态获取类信息并操作对象的能力。
它允许程序在运行时查看任意类的结构(如字段、方法、构造器 | class,Constructor,Field,Method),并通过这些信息创建对象、调用方法、修改属性,即使在编译期不知道具体类型。
运行时类信息的访问
动态创建对象 newInstance(与构造器相同的参数)
动态方法调用
访问和修改字段值
Field field = clazz.getDeclaredField("age");
field.setAccessible(true); // 允许访问私有字段
field.set(obj, 25);
2. getDeclared xxx 和 get xxx 的区别⭐️
getDeclaredField(String name) :返回本类中声明的指定名称的字段(Field),不管访问修饰符(public/private/protected/default)。
getField(String name):返回本类及其父类中声明的 public 字段(必须是 public)。
3. 反射的应用常见⭐️
| 场景 | 示例 |
|---|---|
| 框架开发 | Spring、MyBatis 通过反射创建 Bean、调用方法 |
| JDBC 驱动加载 | Class.forName("com.mysql.cj.jdbc.Driver") 动态加载驱动 |
| 插件系统 | 根据配置文件动态加载并实例化插件类 |
| 序列化/反序列化 | JSON 库(如 Jackson)使用反射解析对象字段 |
注解
1. 什么是注解⭐️
注解(Annotation)是 Java 5 引入的一种元数据形式,用于为代码提供附加信息(metadata),这些信息可以被编译器、开发工具或运行时环境读取和处理,但不会直接影响程序逻辑。
2. 注解的原理与底层实现⭐️
Java 注解(Annotation)是一种元数据机制,其核心原理是:在编译期将注解信息编码到 .class 文件中,运行时通过反射读取这些信息,并由 JVM 内部的 AnnotationInvocationHandler 代理对象提供访问接口。
- 如果注解的
@Retention是SOURCE(如@Override),则不会写入 .class 文件,编译后即丢弃。 - Lombok 等工具利用 编译期注解处理器(APT) 在生成字节码前修改 AST,因此不需要运行时反射。
- Spring、JUnit 等框架依赖
RUNTIME注解,通过反射扫描并执行逻辑。
首先,为了定义注解本身的属性,Java 提供了 5 个标准元注解:
@Retention |
指定注解的生命周期(SOURCE / CLASS / RUNTIME) |
|---|---|
@Target |
指定注解能用在哪些程序元素上(类、方法、字段等) |
@Documented |
是否包含在 JavaDoc 中 |
@Inherited |
是否可被子类继承(仅对类有效) |
@Repeatable |
是否允许重复使用(Java 8+) |
根据注解的生命周期有不同的处理
- 编译期处理:通过 APT(Annotation Processing Tool) 生成代码(如 Lombok、ButterKnife)、
- 运行期处理:通过 反射 获取注解并执行逻辑(如 Spring 的
@Autowired)
3. 注解的作用域⭐️
由 @Retention 决定,控制注解在什么阶段可用:
| 策略 | 含义 | 是否可通过反射获取? | 典型用途 |
|---|---|---|---|
RetentionPolicy.SOURCE |
仅在源码阶段存在,编译后丢弃 | ❌ 否 | @Override, @SuppressWarnings |
RetentionPolicy.CLASS |
编译后保留在 .class 文件中,但JVM 加载时不保留 |
❌ 否 | 少见(Android 注解常用) |
RetentionPolicy.RUNTIME |
保留在 .class 中,且JVM 运行时可通过反射获取 |
✅ 是 | Spring @Component, JUnit @Test |
异常
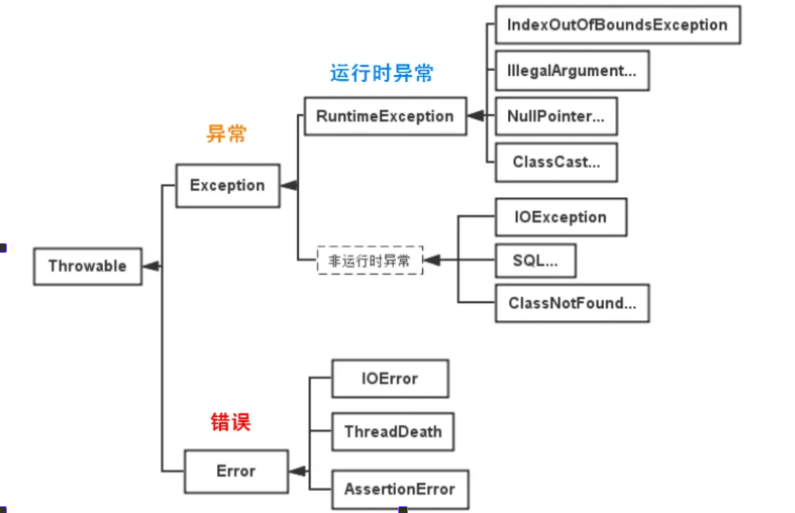
1. 介绍一下 java 异常⭐️
Java 异常是程序运行过程中发生的非正常事件,用于中断当前执行流程并传递错误信息。整个异常体系以 java.lang.Throwable 为根类,主要分为两个子类:Error 和 Exception。
Error 表示 JVM 层面的严重错误,通常由系统资源耗尽或虚拟机内部故障引起。,java 程序无须处理也无法处理,如系统奔溃、栈溢出等等。Exception 则是程序本身可以处理的非正常事件,也就是异常,异常主要分为两大类:
受检异常:编译器强制要求处理的,比如说 IOEeception,SQLException 非受检异常(运行时异常):继承自 RuntimeException 或者 Error,编译器不需要强制处理的。
| 类型 | 说明 | 是否需要处理 | 示例 |
|---|---|---|---|
Error |
JVM 系统级错误,程序无法恢复 | ❌ 不需(也无法)处理 | OutOfMemoryError, StackOverflowError |
Exception |
程序逻辑或外部环境导致的异常 | ✅ 需要处理 | IOException, NullPointerException |
2. java 异常处理有哪些方式⭐️
异常处理主要是通过 try-catch 语句块来捕获和处理异常的,java 中常用的异常处理方式主要有:
try catch 语句块
throw:用于手动抛出异常
throws:在方法签名中声明该方法可能抛出的异常类型,将异常“向上层传递”。
3. 抛出异常为什么不用 throws
具体来说,当异常是非检查异常(Unchecked Exception) 或者在方法内部已被捕获处理时,就不需要在方法签名中声明 throws。
4. try catch 语句的运行情况⭐️
try 块中的代码按顺序执行,一旦抛出异常,将在 catch 块中进行匹配与处理,然后程序将继续执行 catch 块之后的代码,如果没有匹配的代码块,那么异常将会被向上抛出。
- “
finally一定会执行吗?—— 不一定!如System.exit()、JVM 崩溃时不会执行。” - “
catch块只能捕获自身类型或者子类的异常”
try 中有 return |
先执行 finally,再返回 |
|---|---|
catch 中有 return |
先执行 finally,再返回 |
finally 中有 return |
直接返回,覆盖前面的返回值 |
try 中抛出异常,但无 catch |
异常向上抛出,进入调用栈 |
多个 catch 块中,只有第一个与异常类型兼容的会被执行,其余全部跳过;因此应遵循“子类异常在前,父类异常在后”的顺序,否则会导致编译错误或逻辑错误。
5. try{return “a”} finally{return “b”}这条语句返回啥
返回b
6. 为什么设计受检异常⭐️
Java 早期希望通过编译期强制处理 I/O、网络等“可恢复错误”,提升程序健壮性。但现代观点认为这增加了 API 复杂度,因此很多框架(如 Spring JDBC)将受检异常封装为运行时异常。
7. 说出几个常见的运行时异常?
-
NullPointerException(NPE, 空指针异常)- 原因:调用了一个
null对象的方法或属性。 - 地位:Java 异常界的“头号杀手”。
- 原因:调用了一个
-
IndexOutOfBoundsException(数组越界异常)- 原因:访问了数组或集合中不存在的索引(如长度为 5,你访问
index[5])。
- 原因:访问了数组或集合中不存在的索引(如长度为 5,你访问
-
ClassCastException(类型转换异常)- 原因:试图将一个对象强制转换为它不是的子类(如把
Cat对象强转为Dog)。
- 原因:试图将一个对象强制转换为它不是的子类(如把
-
ArithmeticException(算术异常)- 原因:出现了非法的数学运算,最常见的是除数为 0。
-
IllegalArgumentException(非法参数异常)- 原因:传给方法的参数不符合业务逻辑(比如要求传正数,你传了个负数)。
-
NumberFormatException(数字格式化异常) - 原因:试图把非数字的字符串转成数字(如
Integer.parseInt("abc"))。
8. 如何解决空指针异常?
针对 NPE:使用 Java 8 的 Optional、进行非空校验(if (obj != null))或使用 @NonNull 注解。
针对异常处理:运行时异常通常反映了程序的逻辑漏洞,应该通过代码逻辑修复,而不是盲目地用 try-catch 去掩盖。
Object
1. object类有那些方法⭐️
Object 是 Java 中所有类的直接或间接父类,提供了 11 个核心方法,是对象行为的基础。其中最常用的是 equals()、hashCode()、toString() 和 clone() 等,开发者常需重写这些方法以实现自定义逻辑。
| 方法 | 说明 |
|---|---|
equals(Object obj) |
比较两个对象是否相等,默认比较引用地址(与 == 效果相同),建议重写以比较内容 |
hashCode() |
返回对象的哈希码,用于哈希表(如 HashMap、HashSet)中快速查找,必须与 equals() 保持一致 |
toString() |
返回对象的字符串表示,默认为 className@hashCode(16进制表示),建议重写以便调试和日志输出 |
clone() |
创建并返回对象的副本(浅拷贝),需实现 Cloneable 接口,否则抛 CloneNotSupportedException |
finalize() |
JVM 在垃圾回收前调用,用于清理资源,已废弃不推荐使用(Java 9+ 标记为 deprecated) |
getClass() |
返回对象运行时的 Class 对象(可能和编译时不同),用于反射 |
notify() / notifyAll() |
唤醒等待在该对象锁上的线程,用于线程同步 |
wait() |
使当前线程进入等待状态,直到被唤醒或超时,用于线程协作 |
wait(long timeout) / wait(long timeout, int nanos) |
带超时的等待版本 |
wait()(重载) |
多种重载形式,支持超时控制 |
2. == 与 equals 的区别
== 比较的是两个变量的值是否相同,对于基本数据类型,那没问题,但对于引用数据类型,它仅仅比较当前引用指向的地址是否相同,也就是是否指向同一个对象。
String s1 = new String("hello");
String s2 = new String("hello");
System.out.println(s1 == s2); // false(不同对象)
System.out.println(s1.equals(s2)); // true(内容相同)
equals()的默认实现和 == 是一致的,也就是比较两个对象的内存地址是否相同,但在实际开发中对象是否相同往往是根据对象的字段值来比较的,因此,我们需要重写 equals()。
class User {
private int id;
private String name;
@Override
public boolean equals(Object obj) {
if (this == obj) return true;
if (obj == null || getClass() != obj.getClass()) return false;
User user = (User) obj;
return id == user.id;
}
}
和 equals 配套的必须重写 hashCode 方法,因为 Java 的约定是:如果两个对象 equals 返回 true,它们的 hashCode 必须相等;如果 hashCode 不相等,equals 一定返回 false。如果只重写 equals 不重写 hashCode,会导致对象在 HashMap、HashSet 等集合中无法正确存储,比如两个 id 相同的 User 对象,equals 返回 true,但 hashCode 不同,会被当成两个不同元素存入集合。重写示例:
3. hashcode 与 equals 的关系⭐️
在 Java 中,重写 equals() 方法时,通常也需要重写 hashCode() 方法,并需遵循以下两条约定:
- 一致性(Consistency):如果两个对象使用
equals()比较结果为true,那么它们的hashCode()值必须相同。 -
如果两个对象的
hashCode()相同,它们使用equals()比较的结果不一定为true。 -
若只重写
equals()而不重写hashCode(),会导致对象在HashMap、HashSet等集合中无法正确存储或查找。 - 例如:两个
id相同的User对象,equals()返回true,但hashCode()不同,会被当作两个不同元素存入集合。
4. java 里 String 的常用方法有哪些
int length() |
返回字符串长度(字符个数) | "abc".length() → 3 |
boolean equals(Object obj) |
比较两个字符串内容是否完全相同(区分大小写) | "abc".equals("ABC") → false |
String substring(int beginIndex) |
从指定索引开始截取到末尾 | "hello".substring(2) → "llo" |
String trim() |
去除字符串首尾的空白字符(空格、制表符等) | " abc ".trim() → "abc" |
String replace(char oldChar, char newChar) |
替换所有指定字符 | "aaa".replace('a', 'b') → "bbb" |
boolean isEmpty() |
判断字符串长度是否为 0(注意:null 调用会报错,需先判空) |
|
5. String、StringBuffer、StringBuilder的区别与联系
三者都是用于处理字符串的类,但核心差异在于:可变性、线程安全性和性能。String 不可变且线程安全;StringBuilder 可变、高性能但非线程安全;StringBuffer 可变、线程安全但性能略低。
| 特性 | String |
StringBuilder |
StringBuffer |
|---|---|---|---|
| 可变性 | ❌ 不可变(Immutable) | ✅ 可变(Mutable) | ✅ 可变(Mutable) |
| 线程安全 | ✅ 天然线程安全(不可变) | ❌ 非线程安全 | ✅ 线程安全(方法加 synchronized) |
| 性能 | 低(频繁修改时生成大量临时对象) | ⚡ 最高(无同步开销) | 中等(有同步开销) |
| 适用场景 | 字符串常量、少量拼接 | 单线程下频繁修改 | 多线程下频繁修改 |
java8 新特性
1. java 8 你知道有什么新特性吗
-
Lambda 表达式:简化匿名内部类写法。 ()-> {}
-
函数式接口(Functional Interface):只包含一个抽象方法的接口,可用
@FunctionalInterface注解标注。 -
Stream API:提供链式操作处理集合处理,并且支持并行操作来提高处理效率。
-
默认方法(Default Methods):允许在接口中定义带有默认实现的方法。
-
Optional 类:用于避免空指针异常(NullPointerException)。
-
新的日期时间 API(java.time 包):如
LocalDateTime、ZonedDateTime等,替代老旧的Date和Calendar。 -
方法引用(Method Reference):简化Lambda表达式,直接通过
::引用已有方法。 -
重复注解(Repeatable Annotations):允许在同一位置多次使用同一注解。
-
Completable Future:增强异步编程能力,支持链式调用和组合操作
2. Lambda 表达式你了解吗
Lambda表达式是一种简洁的语法,本质是创建匿名内部类,主要用于简化函数式接口的使用(只有一个抽象方法的接口)。
(parameters) -> expression // 当lambda方法体只有一个表达式时使用,默认会返回表达式的结果
() -> {statements;} // 如果方法体有多条语句,需要用{}包裹,如果有返回值需要return
3. java 中 stream 的api 介绍一些
Stream API 提供了一种高效且易于理解的方式来处理数据序列(如 List、Set 等)。主要分为两类操作:
-
中间操作(Intermediate):这些操作返回一个新的
Stream,支持链式调用,不会立即执行(惰性求值),只有在遇到终端操作时才会真正处理数据,例如:filter(Predicate):过滤元素,只保留满足条件的。map(Function):将一个元素 --> 另一种类型/形式flatMap(Function):将每个元素映射为一个流,然后“扁平化”合并成一个流(常用于处理嵌套结构)。sorted(Comparator):对流中元素排序。可传自定义比较器,也可用自然顺序(sorted()无参)。distinct():去除重复元素(基于equals()方法)。limit(n),skip(n):最多保留前 n 个元素、跳过前 n 个元素。
-
终端操作(Terminal):这些操作会触发流的执行,并产生一个非 Stream 的结果(或副作用),每个流只能使用一次终端操作,例如:
forEach(Consumer):遍历每个元素并执行操作(常用于打印、日志等副作用)。collect(Collector):将流元素收集到集合、字符串或其他容器中(最常用终端操作之一)。reduce(BinaryOperator):将流中的元素逐步合并为一个值(如求和、最大值等)。count():返回流中元素的数量(返回long)。findFirst():返回第一个元素(适用于有序流)。findAny():返回任意一个元素(在并行流中更高效)。- `anyMatch()、allMatch()、noneMatch():- 判断是否存在/全部/没有元素满足条件,返回 boolean。
4. 获取 Stream 的方法
| 数据源 | 获取 Stream 的方式 |
|---|---|
| Collection(List/Set 等) | collection.stream() 或 collection.parallelStream() |
| 数组 | Arrays.stream(array) 或 Stream.of(array) |
| 单个值或多个值 | Stream.of("a", "b", "c") |
| 空流 | Stream.empty() |
| 无限流 | Stream.iterate(seed, unaryOperator) 或 Stream.generate(supplier) |
| 文件行 | Files.lines(Path path)(返回 Stream<String>) |
| 数值范围 | IntStream.range(0, 10).boxed()(转为 Stream<Integer>)`IntStream.rangeClosed().boxed() |
为什么原始流需要转为对象流:因为 collect这样的终结流只能操作对象流。 如果将原始流转为对象流:xx.boxed()
5. Stream 流的并行api
并行流就是将数据源通过多个子流来进行多线程操作,然后将处理的结果再汇总为一个流对象,底层是使用通用的 fork/join 池来实现的。 通俗来讲,就是把一个大任务拆分为了多个小任务同时进行,然后再去把这些小任务的结果汇总。
获取并行流的 api 主要有以下
-
直接通过集合对象获取
-
将已有串行流转换为并行流
-
直接创建并行流
重点
有些操作使用并行没什么副作用,比如 collect, reduce, filter, map, flatmap,但是有些操作使用并行流会带来副作用,比如:foreach,还有一些操作会带来很大的性能开销,比如 sorted,distinct, limit。
6. completableFuture怎么用的?
CompletableFuture 是 Java 8 引入的异步编程工具类,是对 Future 的增强,支持链式调用、回调机制、组合操作和异常处理,能有效避免“回调地狱”问题。
💡 “回调地狱”是指多个异步操作嵌套导致代码结构混乱,难以维护。CompletableFuture 通过函数式链式 API 解决了这个问题。
// 使用 Guava ListenableFuture(伪代码)
listenables.addFuture(step1, new FutureCallback<String>() {
@Override
public void onSuccess(String result) {
listenables.addFuture(step2, new FutureCallback<String>() {
@Override
public void onSuccess(String result) {
listenables.addFuture(step3, new FutureCallback<String>() {
@Override
public void onSuccess(String result) {
System.out.println(result);
}
});
}
});
}
});
CompletableFuture<String> result = CompletableFuture.supplyAsync(() -> "Step1")
.thenApply(s -> s + "Step2")
.thenApply(s -> s + "Step3");
result.thenAccept(System.out::println);
6.1 CompletableFuture 的用法
-
创建异步任务
-
设置回调
- thenApply(x -> {}) 接受参数并返回一个值
-
thenAccept(x ->{)) 只接受、无返回值
-
组合多个异步任务
7. java 21 的新特性那有些
7.1 Switch 语句的模式匹配:
该功能在 Java 21 中也得到了增强。它允许在 switch 的 case 标签中使用模式匹配,使操作更加灵活和类型安全,减少了样板代码和潜在错误。例如,对于不同类型的账户类,可以在 switch 语句中直接根据账户类型的模式来获取相应的余额,如:
7.2 数组模式
将模式匹配扩展到数组中,使开发者能够在条件语句中更高效地解构和检查数组内容。例如:
7.3 字符串模板(预览版)
提供了一种更可读、更易维护的方式来构建复杂字符串,支持在字符串字面量中直接嵌入表达式。例如,以前可能需要使用:
7.4 并发新特性
虚拟线程:这是 Java 21 引入的一种轻量级并发的新选择。它通过共享堆栈的方式,大大降低了内存消耗,同时提高了应用程序的吞吐量和响应速度。可以使用静态构建方法、构造器或 ExecutorService 来创建和使用虚拟线程。
Scoped Values(范围值):提供了一种在线程间共享不可变数据的新方式,避免使用传统的线程局部存储,促进了更好的封装性和线程安全,可用于在不通过方法参数传递的情况下,传递上下文信息,如用户会话或配置设置。
序列化
1. 怎么把一个对象从一个 jvm 转到另一个 jvm
要将对象跨JVM传输,可通过序列化+网络传输、消息队列、RPC 或 共享存储 实现。
- 使用序列化和反序列化:将对象序列化为字节流,并将其发送到另一个 JVM,然后在另一个 JVM 中反序列化字节流恢复对象。这可以通过 Java 的 ObjectOutputStream 和 ObjectInputStream 来实现。
- 使用消息传递机制:利用消息传递机制,比如使用消息队列(如 RabbitMQ、Kafka)或者通过网络套接字进行通信,将对象从一个 JVM 发送到另一个。这需要自定义协议来序列化对象并在另一个 JVM 中反序列化。
- 使用远程方法调用(RPC):可以使用远程方法调用框架,如 gRPC,来实现对象在不同 JVM 之间的传输。远程方法调用可以让你在分布式系统中调用远程 JVM 上的对象的方法。
- 使用共享数据库或缓存:将对象存储在共享数据库(如 MySQL、PostgreSQL)或共享缓存(如 Redis)中,让不同的 JVM 可以访问这些共享数据。这种方法适用于需要共享数据但不需要直接传输对象的场景。
2. 序列化和反序列化怎么实现呢?
Java 默认的序列化虽然实现方便,但却存在安全漏洞、不跨语言以及性能差等缺陷。
无法跨语言:Java 序列化目前只适用基于 Java 语言实现的框架,其它语言大部分都没有使用 Java 的序列化框架,也没有实现 Java 序列化这套协议。因此,如果是两个基于不同语言编写的应用程序相互通信,则无法实现两个应用服务之间传输对象的序列化与反序列化。
容易被攻击:Java 序列化是不安全的,我们知道对象是通过在 ObjectInputStream 上调用 readObject() 方法进行反序列化的,这个方法其实是一个神奇的构造器,它可以将类路径上几乎所有实现了 Serializable 接口的对象都实例化。这也就意味着,在反序列化字节流的过程中,该方法可以执行任意类型的代码,这是非常危险的。
序列化后的流太大:序列化后的二进制流大小能体现序列化的性能。序列化后的二进制数组越大,占用的存储空间就越多,存储硬件的成本就越高。如果我们是进行网络传输,则占用的带宽就更多,这时就会影响到系统的吞吐量。
因此,平常在实现序列化的时候,我会优先考虑使用主流的序列化框架。 比如阿里的 fastJson,或者是 Protubuf 来代替 java 序列化。
3. 将对象转换为二进制字节流具体怎么实现
要将对象转换为二进制字节流,本质是序列化过程,即按照特定协议将对象状态转化为字节序列。在 Java 中,主要通过 ObjectOutputStream 和 ObjectInputStream 实现。
java 为我们提供了对象流来进行对象的序列化,我们可以通过 ObjectOutputStream 的 writeObject 来将对象转为二进制流。
之后可以通过 ObjectInputStream.readObject 方法实现二进制流到对象的转换。
4. 什么时候需要实现序列化接口呢?
(1)远程调用,rmq这样的需要通过网络传递对象的二进制数组
(2)在 redis,或者我们自己要将对象写入磁盘实现持久化,也得实现序列化接口
5. 序列化为什么要有版本号
为了保证序列化和反序列化的对象是同一个对象。
IO
IO 基础知识
IO 流介绍
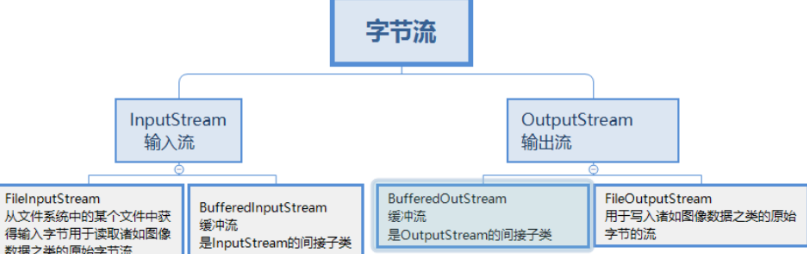
IO 即 Input/Output,输入和输出。数据输入到计算机内存的过程即输入,反之输出到外部存储(比如数据库,文件,远程主机)的过程即输出。数据传输过程类似于水流,因此称为 IO 流。IO 流在 Java 中分为输入流和输出流,而根据数据的处理方式又分为字节流和字符流。
InputStream/Reader: 所有的输入流的基类,前者是字节输入流,后者是字符输入流。OutputStream/Writer: 所有输出流的基类,前者是字节输出流,后者是字符输出流。
字节流
输入输出都是以 byte (8位) 为基本单位,不涉及编码,能处理所有文件(如图片、视频、二进制),是 IO 的底层基础。
字符流
以 char (16位) 为基本单位,内置字符集编解码逻辑,专门用于高效处理纯文本,避免中文乱码。
字节流是“搬运工”,原样搬运二进制;字符流是“翻译官”,会将二进制按编码表翻译成人类文字。
java 中有几种类型的流呢?

IO 设计模式
其他
1. http 常见状态码
-
200 OK //客户端请求成功
-
301 Permanently Moved (永久移除),请求的 URL 已移走。Response 中应该包含一个 Location URL, 说明资源现在所处的位置
-
302 Temporarily Moved 临时重定向
-
400 Bad Request //客户端请求有语法错误,不能被服务器所理解
-
401 Unauthorized //请求未经授权,这个状态代码必须和 WWW-Authenticate 报头域一起使用
-
403 Forbidden //服务器收到请求,但是拒绝提供服务
-
404 Not Found //请求资源不存在,eg:输入了错误的 URL
-
500 Internal Server Error //服务器发生不可预期的错误
-
503 Server Unavailable //服务器当前不能处理客户端的请求,一段时间后可能恢复正常
2. get 和 post 的区别
| 维度 | GET | POST |
|---|---|---|
| 参数位置 | 拼接在 URL 后面(Query String) | 放在 Request Body(请求体)中 |
| 安全性 | 较低(参数暴露在地址栏,会被日志记录) | 较高(适合传输敏感信息) |
| 数据长度 | 受 URL 长度限制(通常 2KB 左右) | 原则上无限制 |
| 幂等性 | 幂等(多次执行结果相同,不修改数据) | 非幂等(多次执行会创建多个资源) |
| 缓存 | 浏览器会主动缓存 | 默认不会缓存 |
而最核心的区别实际是它们的含义不同,GET 是从服务端索取数据,而 POST 是向服务端提交数据的。
3. Cookie 和 Session 的区别
一句话核心: Cookie 存客户端(浏览器),Session 存服务端。