NLP
NLP 概述
自然语言处理(Natural Language Processing, NLP),是人工智能领域的一个重要分支。自然语言,指人类日常使用的语言(如中文、英文),NLP 的目标是让计算机“理解”或“使用”这些语言。
NLP 文本表示
什么是文本预处理?
文本预处理就是在预料输送给模型之前所作的一系列工作,目的是让这些语料满足 LLM 的输入要求。比如,只有将一个一个 token 转换为 embedding,模型才能理解以及对这个 token 做后续的计算。
文本处理的流程 ⭐⭐⭐
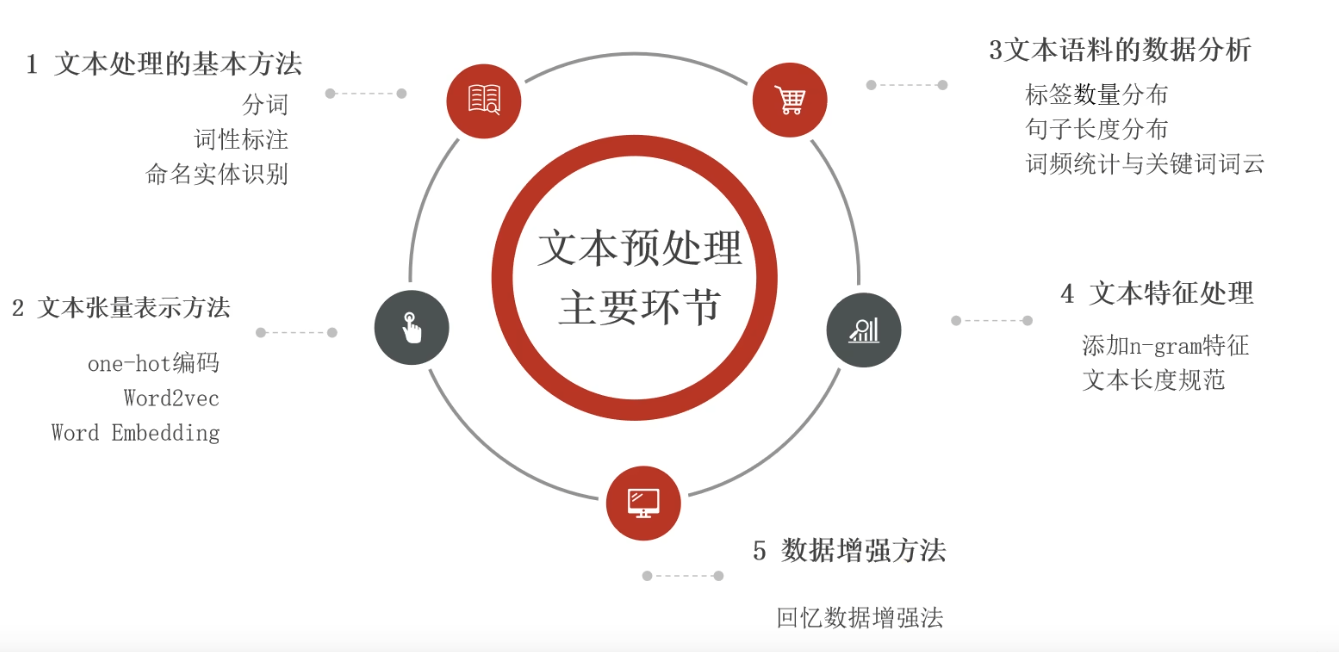
文本处理的基本方式
1. 分词 ⭐⭐⭐
分词(Tokenization)是将原始文本切分为若干具有独立语义的最小单元(即token)的过程,是所有 NLP 任务的起点。
英文分词
英文的分词方式可分为词级(Word-Level)分词、字符级(Character-Level)分词和子词级(Subword-Level)分词。不同方式各有优劣,适用于不同场景。
三种分词方式对比
| 方式 | 词表规模 | OOV 问题 | 语义保留 | 序列长度 | 典型代表 |
|---|---|---|---|---|---|
| 词级分词 | 很大(10万+) | 严重 | 强 | 短 | 传统 NLP 工具 |
| 字符级分词 | 极小(\~256) | 几乎无 | 弱 | 长 | 字符级 CNN/RNN |
| 子词级分词 | 适中(3万\~5万) | 极少 | 中等 | 中 | BERT、GPT 等现代大模型 |
参考教程
BPE 的详细训练与分词过程可参考 Hugging Face 官方课程:Byte-Pair Encoding tokenization。
中文分词
中文分词也分为三种,但是这里就不重复介绍了,只需要知道中文的 “字符” 就是汉字,然后现在主要有两种路线,第一种就是词级分词,代表工具包括 jieba、HanLP等,这些工具广泛应用于传统 NLP 任务中。另一种是基于子词建模算法(如BPE)的方式,代表工具包括 Hugging Face Tokenizer、SentencePiece、tiktoken等,常用于大规模预训练语言模型中。
jieba 是 Python 实现的中文分词库,主要有三种分词模式:
| 模式 | 说明 | 函数 |
|---|---|---|
| 精确模式 | 试图将句子最精确地切开,适合文本分析 | jieba.cut(lcut_all=False) |
| 全模式 | 把句子中所有的可以成词的词语都扫描出来,速度快,但会有歧义 | jieba.cut(cut_all=True) |
| 搜索引擎模式 | 在精确模式基础上,对长词再次切分,提高召回率 | jieba.cut_for_search() |
下面主要演示 jieba 分词器的用法。
官方项目
具体用法详见 jieba GitHub,主要的操作就是分词、加载用户的自定义词典、通过 TF-IDF 算法来提取关键字等。
import jieba
text = '我爱学习,我爱敲代码'
# 精确模式:cut_all=False (默认)
words = jieba.cut(text, cut_all=False)
print('/ '.join(words))
输出:
说明
精确模式会尽量精确地切开句子,保留最合理的分词结果,避免歧义,适合大多数场景。
2. 命名实体识别 - NER
人名、地名、机构名等专业名词统称为命名实体,NER(Named Entity Recongnition) 则是在一段文本中识别出可能存在的命名实体,这个任务是 AI 解决 NLP 领域的重要基础。
3. 词性标注 - POS
词性标注则是标出一段文本中每个词汇的词性,词性是对语言文本的另一个角度的理解,也是 AI 解决 NLP 高阶任务的基础。
from jieba import posseg
# res 是一个生成器
res = posseg.cut("小明硕士毕业于中国科学院计算所,后在日本京都大学深造
# item 是 jieba 自定义的 class,它有 word, flag 这两个属性
for item in res:
print(type(item), item.word, item.flag, sep=" ")
# 输出
<class 'jieba.posseg.pair'> 小明 nr
<class 'jieba.posseg.pair'> 硕士 n
<class 'jieba.posseg.pair'> 毕业 n
<class 'jieba.posseg.pair'> 于 p
<class 'jieba.posseg.pair'> 中国科学院 nt
<class 'jieba.posseg.pair'> 计算所 n
<class 'jieba.posseg.pair'> , x
<class 'jieba.posseg.pair'> 后在 t
<class 'jieba.posseg.pair'> 日本京都大学 nt
<class 'jieba.posseg.pair'> 深造 v
文本表示 ⭐⭐⭐
将一段文本使用张量的形式表示,这个过程就叫做文本张量表示,词表示成词向量,一句话就构成了一个词向量矩阵。做这个转换是因为计算机无法直接理解人类自然语言,所以要把文本转为计算机可以理解和计算的形式,也就是张量。
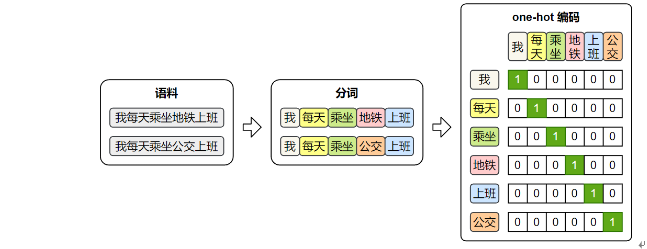
1. one-hot
One-Hot 编码 是最基础的离散表示方法:
- 词汇表大小就是向量维度
- 每个词对应一个向量,仅在该词索引位置为 1,其余位置全为 0
- 优点:简单直观,实现容易
- 缺点:维度灾难(词汇表大时维度极高),并且完全丢弃了词与词之间的联系,无法表示词间语义相关性。
"""
演示独热编码的生成 + 使用
"""
# 词汇表
words = ['周杰伦', '陈奕迅', '王力宏', '吴亦凡', '刘德华']
label = [0, 1, 2, 3, 4]
dic = dict(zip(words, label))
def one_hot(word) -> list:
"""
生成独热编码
:param word:
:return:
"""
if word not in dic:
print('没有该词')
raise ValueError
res = [0] * len(dic)
res[dic[word]] = 1
return res
# 测试
print(one_hot('周杰伦')) # [1, 0, 0, 0, 0]
print(one_hot('陈奕迅')) # [0, 1, 0, 0, 0]
2. word2vec
Word2Vec 是 Google 提出的词嵌入模型,核心思想:
- 通过浅层神经网络在大规模语料上训练,将词映射为低维稠密向量
- 能够捕捉词语义相似度:语义相近的词在向量空间中距离更近
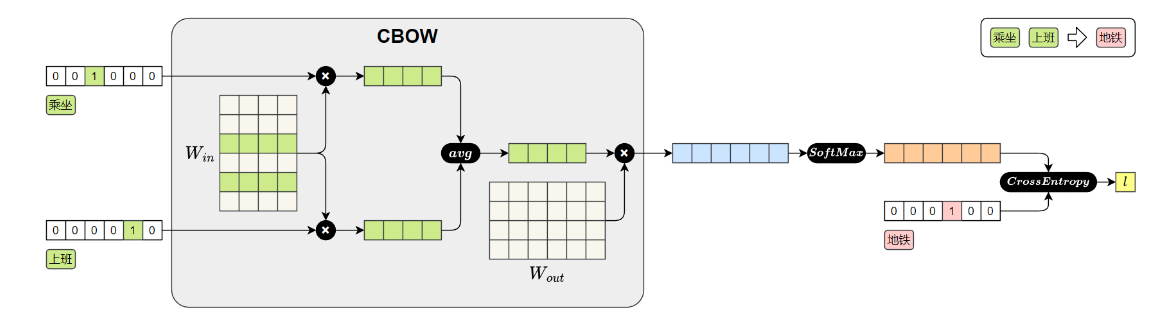
支持两种训练模式:
CBOW:根据上下文预测中心词,适合小规模语料,如下图,神经网络的输入是当前词的上文和下文,目标输出是中心词。
Skip-gram:根据中心词预测上下文,适合大规模语料
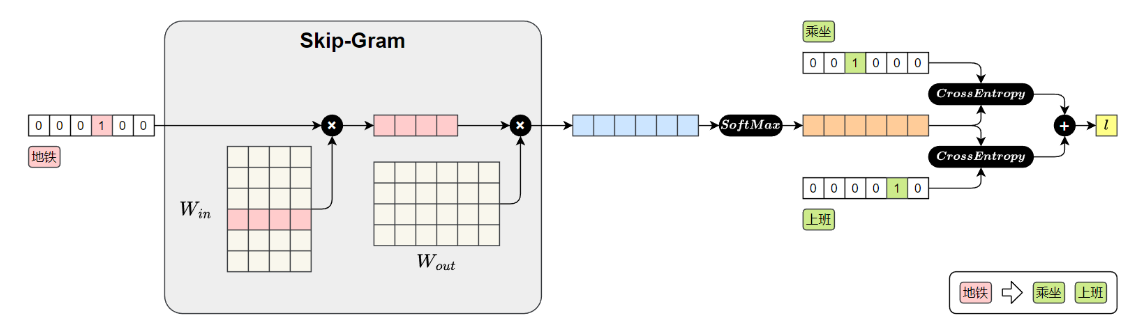
Word2Vec 的出现让词表示进入了 embedding 时代,是 NLP 里程碑式的工作。
下面是通过 FastText 去训练词向量的过程,具体用法参考官方文档。
# 获取与输入词语义最相近的 N 个词
words = model.get_nearest_neighbors("人工智能", k=10)
for similarity, word in words:
print(f"{word}: {similarity:.4f}")
输出示例:
| 参数 | 说明 | 默认值 |
|---|---|---|
model |
训练模式 cbow 或 skipgram |
skipgram |
dim |
词向量维度 | 100 |
ws |
上下文窗口大小 | 5 |
minCount |
最小词频阈值 | 5 |
epoch |
训练轮数 | 5 |
lr |
学习率 | 0.05 |
thread |
线程数 | cpu 核心数 |
第二种方式就是通过 Gensim 库来完成。Gensim 提供了两种使用词向量的方式:加载预训练词向量,或者自行训练。
可使用 KeyedVectors.load_word2vec_format() 加载第三方训练好的词向量文件(如腾讯、微博、Google 等公开词向量)。
from gensim.models import KeyedVectors
model_path = 'sgns.weibo.word.bz2'
model = KeyedVectors.load_word2vec_format(model_path)
示例词向量文件
上述代码使用的 sgns.weibo.word.bz2 词向量文件包含 195,202 个词,每个词向量 300 维。文件可从 Tencent AI Lab Embedding Corpus 下载,也可直接从课程资料获取。
# 查看词向量维度
print(model.vector_size)
# 查看某个词的向量
print(model['地铁'])
# 计算两个向量的相似度
similarity = model.similarity('地铁', '公交')
print('地铁 vs 公交 相似度:', similarity)
余弦相似度
model.similarity 计算的是两个词向量的余弦相似度:
返回值介于 [-1, 1]:
- 接近 1:高度相似,语义接近;
- 接近 0:无明显相关;
- 接近 -1:方向完全相反,极度不相似。
自行训练词向量
准备语料
Word2Vec 的训练语料需要是已分词的文本序列,每个句子是一个 token 列表:
官方文档
Gensim Word2Vec 详细参数与 API 请参考:Gensim Word2Vec 官方文档。
3. word Embedding
Word Embedding(词嵌入) 是更通用的概念:
- 将离散的词映射为低维稠密向量的过程都可称为词嵌入
- 在现代深度学习中,通常指神经网络的 Embedding 层,它是一个可训练的参数矩阵
- 预训练词嵌入(Word2Vec/GloVe)可以直接拿来使用,也可以在下游任务中微调
import torch
import torch.nn as nn
# 词汇表大小 1000,嵌入维度 128
embedding = nn.Embedding(num_embeddings=1000, embedding_dim=128)
# 输入:两个句子,每个句子 5 个词的索引
x = torch.randint(0, 1000, (2, 5)) # [batch_size, seq_len]
# 输出:[batch_size, seq_len, embedding_dim]
output = embedding(x)
print(output.shape) # torch.Size([2, 5, 128])
区别
one-hot:人工编码,稀疏向量,无法训练word2vec:特定的词嵌入训练方法,得到静态词向量word embedding:通用概念,指任何将词转为向量的方法,包括可训练的嵌入层
文本的数据分析
文本数据分析能够帮助我们理解数据语料,快速检查出语料可能存在的问题,它也能一定程度上指导我们的超参数选择。例如,关于标签 Y,分类问题查看标签是否均匀;关于数据 X,查看有没有脏数据,整体数据长度分布等等。
文本特征处理 ⭐⭐⭐
为语料添加具有普适性的文本特征,让模型的处理更加高效。常用的方法:
核心思想:把连续的 n 个词/字符当作一个特征单元,从而捕捉局部上下文信息。
n=1→ unigram(一元语法,单个词)n=2→ bigram(二元语法,连续两个词)n=3→ trigram(三元语法,连续三个词)
作用:增加特征维度,引入上下文信息,提升模型表现;一般取 2-3 足够。
缺点:随着 n 增大,特征空间维度爆炸,特征矩阵极度稀疏。
手动实现 ngram 提取也很简单:
import jieba
def get_ngram(words: list, n:int) -> list:
"""
手动提取 n-gram
:param words: 分词后的词语列表
:param n: n 值
:return: n-gram 列表
"""
res = []
for i in range(len(words) - n + 1):
res.append(' '.join(words[i:i+n]))
return res
# 分词示例
text = '我爱学习自然语言处理'
words = list(jieba.cut(text))
print(f"分词结果: {words}")
# 提取二元语法 (bigram)
print(f"bigram: {get_ngram(words, 2)}")
# 提取三元语法 (trigram)
print(f"trigram: {get_ngram(words, 3)}")
输出:
分词结果: ['我', '爱', '学习', '自然语言', '处理']
bigram: ['我 爱', '爱 学习', '学习 自然语言', '自然语言 处理']
trigram: ['我 爱 学习', '爱 学习 自然语言', '学习 自然语言 处理']
也可以使用 nltk 现成工具:
为什么需要? 深度学习模型训练时,要求一个批次(batch)内所有样本长度一致,因此需要统一规范。
做法: - 超过目标长度的句子 → 截断 - 不足目标长度的句子 → 填充(通常用 0 填充)
import jieba
def standardize_length(words, max_len, pad_token=0):
"""
规范文本长度:截断 + 填充
:param words: 分词后的词索引列表
:param max_len: 目标长度
:param pad_token: 填充标记
:return: 长度统一的列表
"""
if len(words) >= max_len:
# 截断
return words[:max_len]
else:
# 填充
return words + [pad_token] * (max_len - len(words))
# 示例
text = '我爱学习自然语言处理'
words = list(jieba.cut(text))
word2idx = {word: i+1 for i, word in enumerate(words)} # 0 留作填充
indices = [word2idx[w] for w in words]
print(f"原始长度: {len(indices)}, indices: {indices}")
# 测试不同 max_len
print(f"max_len=10: {standardize_length(indices, 10)}")
print(f"max_len=3: {standardize_length(indices, 3)}")
输出:
PyTorch 批量填充 - 自定义实现
对多个变长序列批量填充,手动实现也很简单:
from torch import Tensor
import torch
def sequence_pad_by_custom(sequences: list[Tensor]):
"""
通过自定义实现批量文本长度规范
:param sequences: 多个张量组成的列表,每个张量长度不同
:return: 填充后的张量 [batch_size, max_len]
"""
max_len = max([len(seq) for seq in sequences])
return torch.stack([
torch.cat([seq, torch.zeros(max_len - len(seq))]) for seq in sequences
])
# 测试
seq1 = torch.tensor([1, 2, 3])
seq2 = torch.tensor([4, 5])
seq3 = torch.tensor([6])
print(sequence_pad_by_custom([seq1, seq2, seq3]))
输出:
PyTorch 也内置工具:
文本数据增强方式
文本数据增强 是通过对已有文本进行变换,生成更多相似的训练样本,解决数据不足问题,提升模型泛化能力。常用方法:
核心思想:将原文翻译为另一种语言(如英文),再翻译回原语言(中文),利用不同翻译的表述差异得到新样本,保留原意同时增加句式多样性。
优点:实现简单,不依赖人工,语义一致性高。
import requests
token = 'Bearer ' + 'your_token'
def translate(text, source, dest):
url = 'https://xxx/translation/language/translate'
headers = {
"Content-Type": "application/json",
"Authorization": token
}
body = {
'text': text,
'sourceLang': source,
'targetLang': dest,
'type': '2',
}
res = requests.post(url, headers=headers, json=body)
return res.json()['data']['translatedText']
def back_translate(text: str, mid_lang: str = 'en') -> str:
"""
回译增强:中文 -> 中间语言 -> 中文
:param text: 输入中文文本
:param mid_lang: 中间语言
:return: 回译后的文本
"""
# 中 -> 中间语言
intermediate = translate(text, 'zh', mid_lang)
# 中间语言 -> 中
result = translate(intermediate, mid_lang, 'zh')
return result
# 测试
if __name__ == '__main__':
text = "我爱学习自然语言处理"
print(f"原文:{text}")
print(f"回译:{back_translate(text)}")
输出示例:
随机替换句子中的非停用词为同义词,增加数据多样性。
import jieba
import synonyms
import random
def synonym_replace(text: str, n: int = 1) -> str:
"""同义词替换增强"""
words = list(jieba.cut(text))
new_words = words.copy()
random_replace_count = 0
for _ in range(n):
random_word = words[random.randint(0, len(words)-1)]
synonyms_list = synonyms.nearby(random_word)[0]
if len(synonyms_list) > 0:
idx = random.randint(0, len(synonyms_list)-1)
new_word = synonyms_list[idx]
new_words = [new_word if w == random_word else w for w in new_words]
random_replace_count += 1
return ''.join(new_words)
- 随机插入:在随机位置插入一个同义词
- 随机交换:随机交换两个词的位置
- 随机删除:随机删除一个词
适合数据量足够时,轻微扰动增加模型鲁棒性。
使用大语言模型(如 GPT、LLaMA)对原文进行改写、转述,生成多个不同表述的样本,是当前效果最好的数据增强方式之一。
NLP 传统序列模型 ⭐⭐
在自然语言中,词语的顺序对于理解句子的含义至关重要。虽然词向量能够表示词语的语义,但它本身并不包含词语之间的顺序信息,而这样的序列数据需要专门的网络结构来处理。
序列数据就是元素之间存在先后顺序或者时间依赖关系的数据,比如自然语言文本,股票每天的收盘价、音频与视频。
RNN
1. 概述
循环神经网络 (Recurrent Neural Networks, RNN) 是一种专门用于处理序列数据的神经网络。与传统的前馈神经网络不同,RNN 具有“记忆”能力,能够通过循环连接保存先前步骤的信息,从而捕捉数据在时间维度上的依赖关系。
.png)
循环体现在:上一时间步隐藏层的输出作为下一时间步隐藏层的输入。
2. RNN 结构
RNN 的核心特征是其隐状态 (Hidden State) 的循环传递。在每一个时间步 \(t\),网络接收当前的输入 \(x_t\) 和上一个时间步的隐状态 \(h_{t-1}\),计算出当前的隐状态 \(h_t\)。其基本数学表达式为:
其中 \(\sigma\) 通常为 \(tanh\) 或 \(ReLU\) 激活函数。
梯度消失与梯度爆炸
由于 RNN 在时间链条上共享参数,当序列过长时,反向传播会导致梯度呈指数级衰减或增长,这被称为梯度消失或梯度爆炸问题。为了解决这一痛点,后来演化出了 LSTM 和 GRU 结构。参考:循环层原理的说明
在深入维度之前,需明确 PyTorch 中 nn.RNN 的关键初始化参数,这些参数直接决定了张量(Tensor)的形状。
| 参数 | 说明 |
|---|---|
input_size |
输入特征的数量(例如词向量的维度)。 |
hidden_size |
隐状态(Hidden State)的特征数量。 |
num_layers |
RNN 的层数(堆叠 RNN)。默认为 1。 |
bidirectional |
是否为双向 RNN。默认为 False。 |
3. 输入结构
在 PyTorch 中,RNN 的输入数据通常是一个三维张量。根据 batch_first 参数的不同,维度的顺序会有所区别:
Tensor 形状:
- 若
batch_first=False(默认):(Sequence Length, Batch Size, Input Size) - 若
batch_first=True:(Batch Size, Sequence Length, Input Size)
初始隐状态 \(h_0\): 形状为 (num_layers * num_directions, batch_size, hidden_size)。若不提供,则默认为全 0。
4. 输出结构
RNN 的输出包含两部分,分别对应“所有时间步的记录”和“最后一个时间步的状态”:
-
output: 包含序列中每个时间步产生的隐状态 \(h_t\)。 在单层 RNN 中,维度为
(sequence_len, batch_size, hidden_size),多层的话,前面加一个RNN层维度即可。 -
h_n: 包含序列最后一个时间步的隐状态。维度为
(1,batch_size, hidden_size),多层的话,特别注意,如果是双向RNN 的话,此时不能给 hidden_size * 2,因为我们 h_n 代表的是最后一个时刻的状态,由于正向和反向的“终点”完全不同,它们的状态不能直接拼接,必须作为独立的隐藏状态层保存。维度为:(num_layers * 2, Batch, Hidden)。
5. PyTorch API
在 PyTorch 中,通过 torch.nn.RNN 模块可以快速构建循环层。
import torch
import torch.nn as nn
# 参数说明:input_size=10, hidden_size=20, num_layers=1
rnn = nn.RNN(10, 20, 1, batch_first=True)
# 构造输入数据:(batch_size=3, seq_len=5, input_size=10)
input_data = torch.randn(3, 5, 10)
# 前向传播
output, hn = rnn(input_data)
print(output.shape) # torch.Size([3, 5, 20])
print(hn.shape) # torch.Size([1, 3, 20])
import torch
import torch.nn as nn
# bidirectional=True 开启双向 RNN
# num_layers=2 堆叠两层 RNN
rnn = nn.RNN(10, 20, num_layers=2, batch_first=True, bidirectional=True)
input_data = torch.randn(3, 5, 10)、
output, hn = rnn(input_data)
# 输出维度会因为双向而翻倍 (20 * 2)
print(output.shape) # torch.Size([3, 5, 40])
# hn 维度:(2层 * 2个方向, 3, 20)
print(hn.shape) # torch.Size([4, 3, 20])
官方文档引用
详细的参数列表(如 nonlinearity, dropout 等)请参考:PyTorch nn.RNN 官方文档
6. RNN 的训练过程
RNN 的训练遵循 BPTT (Backpropagation Through Time,随时间反向传播) 算法。
前向传播 (Forward Pass):
- 按照时间步 \(t_1, t_2, \dots, t_n\) 依次输入数据。
- 每个时刻计算隐状态 \(h_t\) 并产生输出 \(y_t\)。
- 核心点:在训练阶段,我们通常拥有完整的真实序列。
计算损失 (Loss Calculation):
将每个时刻的预测值 \(y_t\) 与真实标签(Ground Truth)进行对比,计算总损失 \(Loss = \sum L_t\)。
反向传播 (BPTT):
- 误差不仅在每一层之间传播,还要跨越时间步向后传播。
- 参数共享:由于 RNN 在所有时间步使用相同的 \(W_{ih}\) 和 \(W_{hh}\),梯度会在所有时间步上累加,最后统一更新参数。
Teacher Forcing 技巧
在训练文本生成模型(如翻译)时,为了防止前一步预测错导致后面步步错,通常会使用 Teacher Forcing:即无论模型上一步输出什么,下一步的输入都强制使用真实的标签。
7. RNN 总结
RNN 是一类专门用于处理序列数据的神经网络,核心特点是参数共享和循环连接,使得网络能够保留历史信息并对序列进行建模。
优点:
- 能够捕捉序列数据中的时间依赖关系
- 输入长度可变,理论上可以处理任意长度的序列
- 相比全连接网络,参数更少,计算更高效
缺点:
- 由于循环结构,无法并行计算,训练速度较慢
- 长序列上容易出现梯度消失或梯度爆炸
- 实际中很难真正保留远距离依赖信息
为了解决传统 RNN 的缺陷,研究者提出了 LSTM 和 GRU 等改进结构,通过门控机制更好地控制信息流动,有效缓解了长序列梯度消失问题,成为 NLP 任务中更常用的基础模块。
LSTM
1. 概述
LSTM(Long Short-Term Memory)也称长短期记忆网络,是传统 RNN 的改进版本。传统 RNN 在面对长序列数据时,容易出现梯度消失或梯度爆炸问题,无法有效保留远距离的依赖信息。
LSTM 通过引入门控机制和细胞状态 (Cell State),能够更好地控制信息流动,有效缓解长序列梯度消失问题,能够捕捉长距离语义依赖,是目前 NLP 任务中广泛使用的循环结构。
2. LSTM 结构
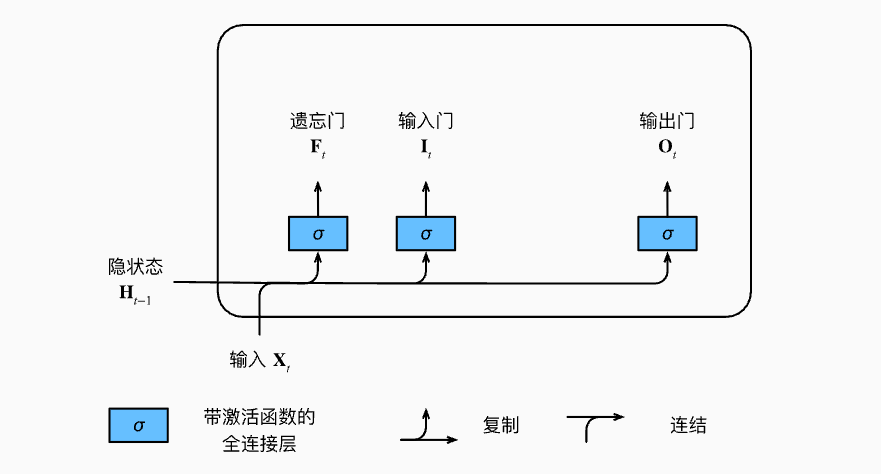
LSTM 的核心是细胞状态 (Cell State) \( C_t \),它像一条传送带贯穿整个时间链条,承载着历史信息(本质上,就是贯穿整个时间链路的一个长期记忆)。LSTM 通过三个门控结构来控制细胞状态的信息流动:
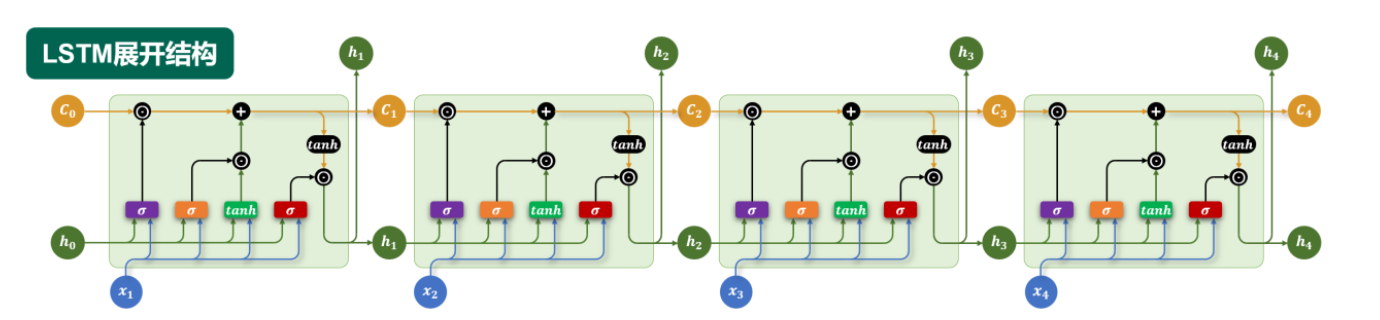
- 遗忘门 \( f_t \):决定从细胞状态中丢弃哪些信息
- 输入门 \( i_t \):决定哪些新信息要存入细胞状态
- 输出门 \( o_t \):决定基于细胞状态输出什么
遗忘门 (Forget Gate)
决定从上一时刻的细胞状态 \(( C_{t-1})\) 中保留多少信息:
- 输出范围 \( [0, 1] \),1 表示"完全保留",0 表示"完全丢弃"
输入门 (Input Gate)
分为两步:
(1)决定哪些新信息要更新到细胞状态
(2)生成候选细胞状态 \(\tilde{C}_t\)
更新细胞状态
更新细胞状态 \(C_t\):
- \(f_t \odot C_{t-1}\):遗忘不需要的信息
- \(i_t \odot \tilde{C}_t\):添加新候选信息
输出门 (Output Gate)
决定当前时刻的隐状态输出 \( h_t \):
核心思想
LSTM 通过门控机制实现了选择性记忆:重要信息长期保存,不重要信息及时遗忘,从而解决传统 RNN 在长序列上梯度消失的问题。
3. 输入结构
在 PyTorch 中,LSTM 的输入数据形状和 RNN 一致:
Tensor 形状:
- 若
batch_first=False(默认):(Sequence Length, Batch Size, Input Size) - 若
batch_first=True:(Batch Size, Sequence Length, Input Size)
初始状态:
- 初始隐状态 \( h_0 \):形状
(num_layers * num_directions, batch_size, hidden_size) - 初始细胞状态 \( c_0 \):形状和 \( h_0 \) 相同
- 若不提供,则默认为全 0
4. 输出结构
LSTM 的输出包含三部分:
output: 包含序列中每个时间步的隐状态 \( h_t \)。
- 维度:若
batch_first=True→(batch_size, sequence_len, hidden_size * num_directions)
h_n: 序列最后一个时间步的隐状态。
- 维度:
(num_layers * num_directions, batch_size, hidden_size)
c_n: 序列最后一个时间步的细胞状态。
- 维度:和
h_n相同 →(num_layers * num_directions, batch_size, hidden_size)
双向 LSTM 维度说明
和 RNN 一样,如果是双向 LSTM,h_n 和 c_n 中正向和反向分别保存,维度直接翻倍,而不是在 hidden_size 维度拼接。output 才是在 hidden_size 维度拼接。
6. PyTorch API
在 PyTorch 中,通过 torch.nn.LSTM 模块可以快速构建 LSTM 层。
torch.nn.LSTM(
input_size, # 输入特征的维度
hidden_size, # 隐藏层的维度
num_layers=1, # LSTM 堆叠的层数
bias=True, # 是否使用偏置项
batch_first=False, # 输入数据是否以 batch_size 为第一维度
dropout=0, # 层与层之间的 Dropout 概率
bidirectional=False, # 是否使用双向 LSTM
proj_size=0, # 隐藏状态的投影维度(用于降维)
device=None, # 指定计算设备(如 'cpu', 'cuda')
dtype=None # 指定数据类型(如 torch.float32)
)
import torch
import torch.nn as nn
# 参数说明:input_size=10, hidden_size=20, num_layers=1
lstm = nn.LSTM(input_size=10, hidden_size=20)
# 构造输入数据:(seq_len=5, batch_size=3, input_size=10)
x = torch.randn(5, 3, 10)
# 构造初始隐状态 + 细胞状态
h0, c0 = torch.randn(1, 3, 20), torch.randn(1, 3, 20)
# 前向传播
output, (hn, cn) = lstm(input_data)
print(output.shape) # torch.Size([5, 3, 20])
print(hn.shape) # torch.Size([1, 3, 20])
print(cn.shape) # torch.Size([1, 3, 20])
import torch
import torch.nn as nn
# bidirectional=True 开启双向 LSTM
# num_layers=2 堆叠两层 LSTM
lstm = nn.LSTM(10, 20, num_layers=2, bidirectional=True)
input_data = torch.randn(5, 3, 10)
output, (hn, cn) = lstm(input_data)
# output 维度:hidden_size 因为双向翻倍 (20 * 2)
print(output.shape) # torch.Size([5, 3, 40])
# hn 维度:(2层 * 2个方向, 3, 20)
print(hn.shape) # torch.Size([4, 3, 20])
print(cn.shape) # torch.Size([4, 3, 20])
官方文档引用
详细的参数列表请参考:PyTorch nn.LSTM 官方文档
7. LSTM 总结
核心改进:相比传统 RNN,LSTM 引入细胞状态和三门控结构,能够有效保留长距离依赖,缓解梯度消失问题
-
优点:
-
能够捕捉长序列中的依赖关系
- 相比传统 RNN,梯度更稳定,不容易消失
-
在 NLP 各类任务(序列标注、文本分类、机器翻译)中表现稳定
-
缺点:
-
计算复杂度比 RNN 更高
- 仍然是循环结构,无法并行计算,训练速度比 Transformer 慢
LSTM 是 RNN 家族最成功的变体,在 Transformer 出现之前,是 NLP 任务的主流选择,至今仍是很多场景下的坚实 baseline。
GRU
1. 概述
GRU(Gated Recurrent Unit)是 LSTM 的简化改进版本,由 Cho 等人在 2014 年提出。它将 LSTM 中的遗忘门和输入门合并为一个更新门,同时合并了细胞状态和隐状态,整体结构更简单,参数更少,训练速度更快,在很多任务上效果和 LSTM 相当。
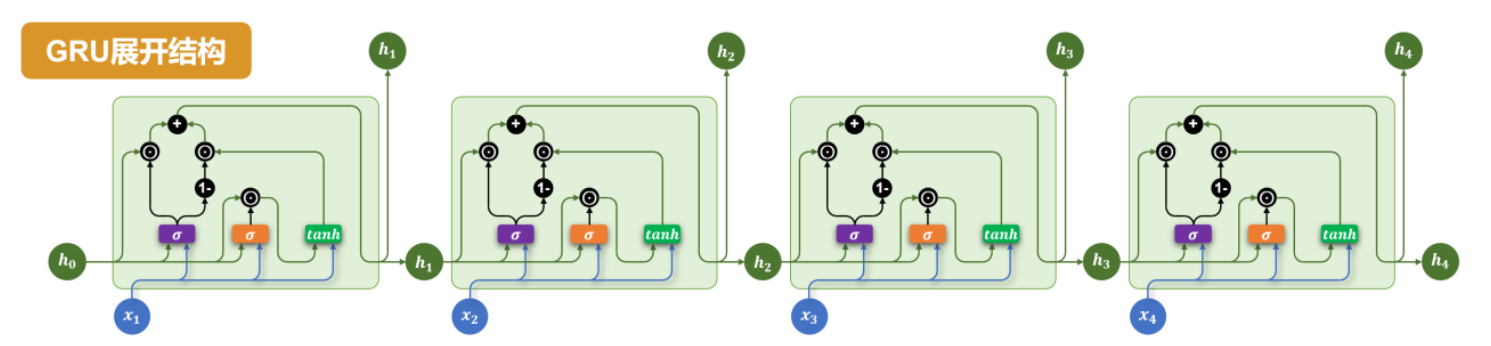
2. GRU 结构
GRU 只有两个门控结构:更新门 \(z_t\) 和 重置门 \(r_t\),只维护一个隐状态 \(h_t\),没有单独的细胞状态。
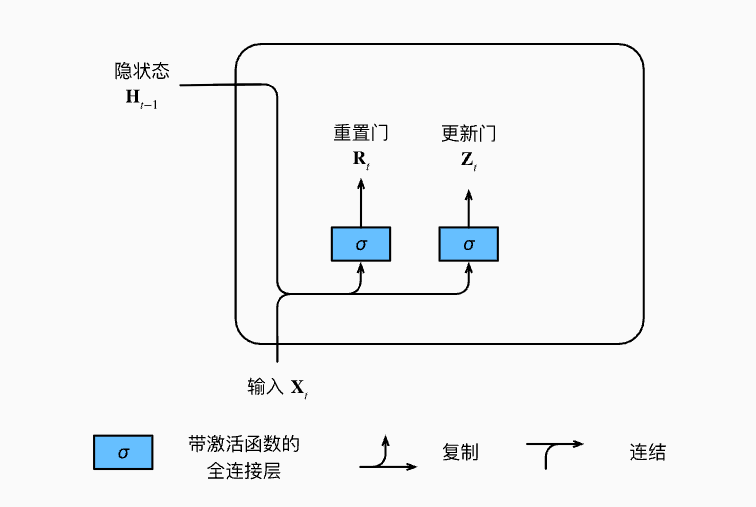
更新门 (Update Gate)
决定保留多少历史信息以及融入多少新信息:
- 输出范围 \([0, 1]\),越接近 1 表示越遗忘历史消息,融入越多的新消息
- 相当于 LSTM 中 遗忘门 + 输入门 的结合
重置门 (Reset Gate)
控制历史隐状态 \(h_{t-1}\) 有多少信息会被用于计算当前候选隐状态 \(\tilde{h}_t\):
- 输出范围 \([0, 1]\)
- \(r_t\) 越接近 0 → 越少历史信息会被保留,更多地忽略历史,相当于"重置"了历史状态
- \(r_t\) 越接近 1 → 越多历史信息会被保留
候选隐状态
计算当前时刻的候选隐状态 \(\tilde{h}_t\):
- \(r_t \odot h_{t-1}\) 按重置门决定保留多少历史信息
- 然后和当前输入 \(x_t\) 结合,经过 \(tanh\) 激活得到候选隐状态
最终隐状态
组合历史信息和候选信息,得到最终隐状态:
- \((1 - z_t) \odot h_{t-1}\):对历史隐状态按更新门加权
- \(z_t \odot \tilde{h}_t\):对候选隐状态按更新门加权
GRU vs LSTM
- GRU:只有 2 个门,参数更少,训练更快,没有单独的细胞状态
- LSTM:有 3 个门,维护单独的细胞状态,参数更多
- 实验表明两者效果接近,GRU 训练更快,因此现在越来越多人使用 GRU
3. 输入结构
在 PyTorch 中,GRU 的输入数据形状和 RNN/LSTM 一致:
Tensor 形状:
- 若
batch_first=False(默认):(Sequence Length, Batch Size, Input Size) - 若
batch_first=True:(Batch Size, Sequence Length, Input Size)
初始状态:
- 初始隐状态 \( h_0 \):形状
(num_layers * num_directions, batch_size, hidden_size) - GRU 没有单独的细胞状态,只需要提供 \( h_0 \)
- 若不提供,则默认为全 0
4. 输出结构
GRU 的输出包含两部分(比 LSTM 少了细胞状态):
output: 包含序列中每个时间步的隐状态 \( h_t \)。
- 维度:若
batch_first=True→(batch_size, sequence_len, hidden_size * num_directions)
h_n: 序列最后一个时间步的隐状态。
- 维度:
(num_layers * num_directions, batch_size, hidden_size)
双向 GRU 维度说明
和 RNN/LSTM 保持一致:如果是双向 GRU,h_n 中正向和反向分别保存,维度直接翻倍,output 在 hidden_size 维度拼接。
5. PyTorch API
在 PyTorch 中,通过 torch.nn.GRU 模块可以快速构建 GRU 层。
import torch
import torch.nn as nn
# 参数说明:input_size=10, hidden_size=20, num_layers=1
gru = nn.GRU(10, 20, 1, batch_first=True)
# 构造输入数据:(seq_len=5, batch_size=3, input_size=10)
input_data = torch.randn(3, 5, 10)
# 前向传播,h0 默认为全 0
output, hn = gru(input_data)
print(output.shape) # torch.Size([5, 3, 20])
print(hn.shape) # torch.Size([1, 3, 20])
import torch
import torch.nn as nn
# bidirectional=True 开启双向 GRU
# num_layers=2 堆叠两层 GRU
gru = nn.GRU(10, 20, num_layers=2, bidirectional=True)
input_data = torch.randn(5, 3, 10)
output, hn = gru(input_data)
# output 维度:hidden_size 因为双向翻倍 (20 * 2)
print(output.shape) # torch.Size([5, 3, 40])
# hn 维度:(2层 * 2个方向, 3, 20)
print(hn.shape) # torch.Size([4, 3, 20])
官方文档引用
详细的参数列表请参考:PyTorch nn.GRU 官方文档
6. GRU 总结
核心改进:GRU 是 LSTM 的简化版,将遗忘门和输入门合并为更新门,去掉了单独的细胞状态,参数更少
优点:
- 结构比 LSTM 简单,参数更少,训练速度更快
- 效果和 LSTM 相当,大多数任务表现接近
- 缓解了传统 RNN 的梯度消失问题
缺点:
- 仍然是循环结构,无法并行计算,训练速度比 Transformer 慢
- 对超长序列依赖的捕捉能力略逊于 LSTM
在实际工程中,如果追求速度和轻量化,GRU 是很好的选择;如果追求效果,LSTM 仍然是更稳妥的选择。两者都是 RNN 家族非常成功的设计。
NLP Seq2Seq 模型
概述
传统的自然语言处理任务(如文本分类、序列标注)以静态输出为主,其目标是预测固定类别或标签。然而,现实中的许多应用需要模型动态生成新的序列,例如:
- 机器翻译:输入中文句子,输出对应的英文翻译
- 文本摘要:输入长篇文章,生成简短的摘要
这些任务的共同特性就是输入和输出均为序列,同时输入输出的长度是动态的,不相同的,为了解决这类问题,研究者提出了Seq2Seq模型。
NLP 注意力机制
self attention
1. 概述
自注意力(Self-Attention),也称为内部注意力(Intra-Attention),是 Transformer 模型的核心组件,由 Google 在 Attention Is All You Need 论文中提出。
核心思想
自注意力允许一个序列内部的每个 token "关注" 序列中其他所有 token,并通过计算注意力权重,为当前 token 生成一个融合了上下文信息的新表示。简单来说,就是让模型在处理每个词时,都会考虑这句话中其他词对它的影响。
相较于传统的 RNN/LSTM 序列模型,自注意力带来了两个关键优势:
- 支持全并行计算:所有位置可以同时计算,无需按时间步递归,大幅加快训练速度
- 更好捕捉长距离依赖:直接建立任意两个 token 之间的连接,解决长序列梯度消失问题
一句话总结:自注意力(Self-Attention)能够让序列中每个位置动态关注序列中其他位置的信息,通过学习注意力权重加权聚合上下文,从而更好地捕捉长距离依赖,避免传统循环神经网络在长序列上的梯度消失和信息遗忘问题,同时支持全并行计算,模型更灵活高效。
2. 直观理解
我们用一个例子来理解自注意力:
The animal didn't cross the street because it was too tired.
句子中 "it" 指代的是什么?人类一看就知道指代的是 "The animal",而不是 "street"。自注意力机制就是让模型在计算每个词的表示时,能够自动捕捉到这种长距离依赖关系,将相关词的语义信息融入当前词。
3. QKV 计算过程
自注意力的核心是通过 Query(查询)、Key(键)、Value(值) 三个投影来计算注意力权重,过程如下:
第一步:对每个 token 生成 Q, K, V
对于输入序列中每个 token 的 embedding x_i,通过三个可训练的权重矩阵 W_q, W_k, W_v 分别投影得到:
- Query(查询向量):表示当前位置的需求,是触发注意力计算的需求向量 —— "我当前这个位置要查找什么信息"
- Key(键向量):表示每个位置作为被关注对象的索引(关键字),用来和 Query 计算相似度 —— "我当前这个位置有什么信息可以提供"
- Value(值向量):表示每个位置实际包含的内容,是最终要获取的实际信息 —— "我当前这个位置具体提供的信息是什么"
在这个过程中,Q 和 K 比较相关性,然后再从 V 中提取你关心的内容。
Q 来源确实很灵活
Q 的来源取决于你要在哪里做注意力:
| 场景 | Q 来源 | 说明 |
|---|---|---|
| 自注意力 | QKV 都来自同一个序列的每个位置 | 每个 token 自己去查自己序列里的其他 token |
| Encoder-Decoder 交叉注意力 | Q 来自 Decoder 当前隐状态 \( s_{t-1} \) | 因为Decoder要根据当前已经解码的内容,去Encoder输入里找相关信息 |
| 也可以是词向量 | Q 就是当前要输出词的词向量 | 本质上还是用当前位置信息去表达"需求",一样的道理 |
核心永远是:Query = 当前位置的需求,我想要找什么 → 去和各个位置的 Key 比相似度。
第二步:计算注意力分数
为了得到当前位置 i 对序列中所有位置 j 的注意力分数,我们计算 Query q_i 和所有 Key k_j 的点积:
点积越大,表示两个词的相关性越高,也就是 i 更需要关注 j。
第三步:缩放与 softmax
为了防止点积结果过大导致 softmax 梯度太小,我们进行缩放:
其中 d_k 是 Key 的维度,缩放的目的是保持点积结果的方差稳定。
经过 softmax 后,所有分数归一化为 Σ α_{i,j} = 1,这就是最终的注意力权重。
第四步:加权求和得到输出
最终输出 z_i 是所有 V 的加权和,权重就是上面得到的注意力分数:
这样,z_i 就融合了整个序列中所有其他 token 对当前 token i 的上下文信息。
4. 矩阵形式的整体计算
把整个序列的 Q, K, V 堆叠成矩阵,我们可以用一次矩阵乘法完成整个自注意力计算:
这正是自注意力能够并行计算的原因:所有输出可以通过一次矩阵乘法得到,无需逐个时间步计算。
5. PyTorch 手动实现
自注意力的实现非常直观,下面是纯 PyTorch 手动实现:
import torch
import torch.nn as nn
import torch.nn.functional as F
class SelfAttention(nn.Module):
def __init__(self, embed_dim):
super().__init__()
self.embed_dim = embed_dim
# 定义 Q, K, V 投影矩阵
self.W_q = nn.Linear(embed_dim, embed_dim)
self.W_k = nn.Linear(embed_dim, embed_dim)
self.W_v = nn.Linear(embed_dim, embed_dim)
def forward(self, x):
"""
Args:
x: 输入张量 shape: (batch_size, seq_len, embed_dim)
Returns:
output: 自注意力输出 shape: (batch_size, seq_len, embed_dim)
attn_weights: 注意力权重 shape: (batch_size, seq_len, seq_len)
"""
batch_size, seq_len, embed_dim = x.shape
# 1. 计算 Q, K, V
q = self.W_q(x) # (batch, seq_len, embed_dim)
k = self.W_k(x) # (batch, seq_len, embed_dim)
v = self.W_v(x) # (batch, seq_len, embed_dim)
# 2. 计算点积分数,并缩放
# (batch, seq_len, seq_len)
scores = torch.bmm(q, k.transpose(1, 2)) / torch.sqrt(torch.tensor(embed_dim))
# 3. softmax 得到注意力权重
attn_weights = F.softmax(scores, dim=-1) # (batch, seq_len, seq_len)
# 4. 加权求和得到输出
output = torch.bmm(attn_weights, v) # (batch, seq_len, embed_dim)
return output, attn_weights
使用示例:
# 测试:batch_size=2, seq_len=5, embed_dim=128
batch_size, seq_len, embed_dim = 2, 5, 128
x = torch.randn(batch_size, seq_len, embed_dim)
self_attn = SelfAttention(embed_dim)
output, attn = self_attn(x)
print(f"输入形状: {x.shape}") # torch.Size([2, 5, 128])
print(f"输出形状: {output.shape}") # torch.Size([2, 5, 128])
print(f"注意力权重形状: {attn.shape}") # torch.Size([2, 5, 5])
6. 掩码自注意力 (Masked Self-Attention)
在解码器(Decoder)中,为了保证每个位置只能看到它前面的位置,不能看到未来的信息,需要使用掩码自注意力。
实现方式很简单:在 softmax 之前,把未来位置的分数设为 -∞,这样 softmax 后对应的注意力权重就是 0,不会参与计算。
def forward(self, x):
batch_size, seq_len, embed_dim = x.shape
q = self.W_q(x)
k = self.W_k(x)
v = self.W_v(x)
scores = torch.bmm(q, k.transpose(1, 2)) / torch.sqrt(torch.tensor(embed_dim))
# === 添加掩码 ===
# 生成下三角掩码:只保留当前位置及之前的位置
mask = torch.tril(torch.ones(seq_len, seq_len, device=x.device)).bool()
scores = scores.masked_fill(~mask, -float('inf'))
attn_weights = F.softmax(scores, dim=-1)
output = torch.bmm(attn_weights, v)
return output, attn_weights
为什么叫'自'注意力?
传统注意力机制通常是"源-目标"注意力(Encoder-Decoder Attention):Query 来自目标序列,Key 和 Value 来自源序列。 而自注意力中,Query、Key、Value 都来自同一个序列,所以叫"自"注意力。
Scaled Dot-Product 为什么要缩放?
如果 d_k 很大,Q 和 K 的点积的方差会变大,导致点积结果绝对值很大,这会让 softmax 函数进入饱和区,梯度变得极小,训练不稳定。
除以 sqrt(d_k) 可以让点积的方差保持为 1,训练更稳定。
参考文档
- 原始论文:Attention Is All You Need
- 经典注意力论文:Neural Machine Translation by Jointly Learning to Align and Translate (Bahdanau et al.)
- PyTorch 官方文档:nn.MultiheadAttention
Encoder-Decoder 结构
1. 传统 seq2seq 的问题
在注意力机制被提出之前,经典的 Encoder-Decoder(编码-解码) 结构(也叫 seq2seq)工作流程是:
- Encoder:将整个输入序列编码为一个固定维度的上下文向量
C - Decoder:根据这个上下文向量
C,逐字生成输出序列
这种方式存在一个明显缺陷:
无论输入序列多长,Encoder 都要把所有信息压缩进一个固定长度的向量。当输入序列很长时,这个向量无法完整保存全部信息,前面的信息会被稀释或遗忘,导致翻译等任务效果下降。
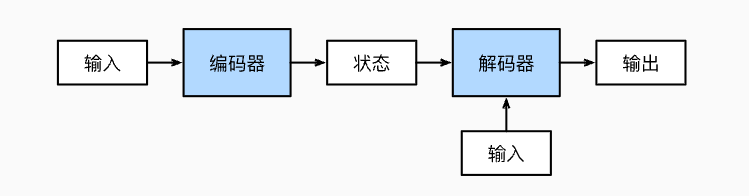
2. 注意力机制解决了什么问题
注意力机制的核心改进:让 Decoder 在每一步生成时,都能"回头看"一眼 Encoder 对输入序列的所有隐状态,通过注意力权重动态关注和当前输出最相关的输入部分,而不是只依赖一个压缩好的固定向量。
这样,即使输入很长,每一步输出都能精准定位到自己需要关注的输入部分,大大缓解了长序列信息遗忘的问题。
3. Decoder 加入注意力机制的计算过程
我们以机器翻译任务为例,输入是中文序列,输出是英文序列,详细介绍注意力机制在 Decoder 中是如何工作的:
符号说明
- 输入序列(源语言):\( x_1, x_2, \dots, x_{T_x} \)
- Encoder 输出的所有隐状态:\( h_1, h_2, \dots, h_{T_x} \)(每个 \( h_i \) 对应输入的一个词)
- Decoder 当前时刻的隐状态:\( s_{t-1} \)(上一步解码后的隐状态)
第一步:计算注意力分数 \( e_{t,i} \)
对于 Decoder 当前要输出第 \( t \) 个词,我们需要计算 Decoder 隐状态 \( s_{t-1} \) 对每个输入隐状态 \( h_i \) 的注意力分数,表示它们的相关性:
align 是对齐函数,常用的计算方式有几种:
| 计算方式 | 公式 | 说明 |
|---|---|---|
| 点积 | \(e = s_{t-1} \cdot h_i\) | 最简单直接 |
| 拼接+MLP | \(e = v^T \text{tanh}(W[s_{t-1}; h_i]\) | 原始论文 Bahdanau 注意力 |
| 乘性 | \(e = s_{t-1}^T W h_i\) | 比拼接更高效 |
第二步:softmax 归一化得到注意力权重 \(\alpha_{t,i}\)
所有 \(\alpha_{t,i}\) 加起来等于 1,表示对各个输入位置的关注程度分布。
第三步:加权求和得到上下文向量 \( c_t \)
上下文向量 \(c_t\) 是所有输入隐状态的加权和,权重就是上面得到的注意力分数:
这个 \(c_t\) 就包含了当前输出位置 \(t\) 最需要关注的输入信息。
第四步:结合上下文向量预测输出
最后,把上下文向量 \( c_t \) 和 Decoder 当前隐状态 \( s_{t-1} \) 拼接起来,送到输出层预测下一个词:
其中 \( s_t \) 是 RNN 根据 \( s_{t-1} \) 和上一个输出 \( y_{t-1} \) 更新得到的隐状态。
4. 总结注意力机制工作流程
整个过程可以概括为四步:
- 算分数:Decoder 当前状态和所有 Encoder 隐状态计算相关性分数
- 归一化:softmax 将分数转为概率分布(注意力权重)
- 加权和:加权求和得到针对当前步的动态上下文向量
- 预测输出:结合上下文向量和 Decoder 状态预测输出
5. 和自注意力的区别
| 对比维度 | Encoder-Decoder 注意力 | 自注意力 |
|---|---|---|
| Q 来源 | Decoder 隐状态 | 输入序列本身 |
| KV 来源 | Encoder 所有隐状态 | 输入序列本身 |
| 作用 | 建立输入输出的对齐 | 建立输入序列内部依赖 |
| 名称 | 交叉注意力(Cross Attention) | 自注意力(Self Attention) |
在 Transformer 中,两种注意力都用到了:
- Encoder 内部用自注意力
- Decoder 的中间层用交叉注意力(Q 来自 Decoder,KV 来自 Encoder)
attention 机制的分类
注意力机制可以根据不同的计算方式分为几大类:
| 类型 | 计算方式 | 特点 | 可导性 |
|---|---|---|---|
| Soft Attention(软注意力) | 对所有位置计算注意力权重,然后加权求和 | 每个位置都参与,权重是 0~1 之间的概率 | ✅ 处处可导,可以直接端到端训练 |
| Hard Attention(硬注意力) | 只选一个或少数几个位置来关注 | 离散选择,更符合人类"一次只关注一处"的直觉 | ❌ 不可导,需要用强化学习等方法训练 |
| Global Attention(全局注意力) | 关注 Encoder 所有位置的隐状态 | 计算完整,效果好但慢 | ✅ 可导 |
| Local Attention(局部注意力) | 只关注 Encoder 一个小窗口内的位置 | 比全局更快,平衡效果和效率 | ✅ 可导 |
| Self-Attention(自注意力) | QKV 都来自同一个序列 | 捕捉序列内部依赖,不需要循环 | ✅ 可导,支持并行 |
Soft Attention 是现在最常用的,Transformer 中用的就是软注意力。Hard Attention 因为训练复杂,实际用得比较少。
一句话总结核心区别:
软注意力给所有人打分加权,一次看完全部;硬注意力只挑少数几个重点看。
attention 机制的计算规则
1. 目标说明
注意力机制的计算可以概括为两大步,目标是把原始的 Query 升级为融合上下文信息的更强表示:
- 第 1 步:用查询张量
Q与所有Key进行相似度运算,得到注意力权重分布(每个位置的权重系数) - 第 2 步:用权重分布对
Value加权求和,得到注意力机制的最终结果
核心思想:把"普通的 q 升级成一个更强大的 q",让它包含上下文信息。
2. 常见计算公式
根据相似度的计算方式不同,常见有几种规则:
- 属于加性注意力(Additive Attention)
- 先把 Q 和 K 拼接,再通过一个线性层计算相似度
- 当 Q 和 K 维度不同时也能用
- 是经典 Encoder-Decoder 注意力(Bahdanau 论文)
- 在拼接线性后加了一层 tanh 非线性,进一步拟合复杂相似度
- 同样用于传统 Encoder-Decoder 注意力
3. 适用场景
| 公式 | 适用场景 |
|---|---|
| 加法/非线性注意力 | 传统 RNN 版 Encoder-Decoder 注意力(软/硬注意力都可用) |
| 缩放点积注意力 | Transformer 自注意力、交叉注意力 |
前两种主要用于传统 Encoder-Decoder 的注意力机制,第三种就是 Transformer 里用的自注意力。
attention 代码编写 ⭐⭐⭐
下面给出几种常见注意力机制的完整 PyTorch 手动实现:
Bahdanau 加法注意力 批量版本,支持 batch 数据,Query 和每个 Key 分别拼接计算分数。
import torch
import torch.nn as nn
import torch.nn.functional as F
class BahdanauAttention(nn.Module):
def __init__(self, q_dim, k_dim, v_dim, out_dim):
"""
初始化 Bahdanau 加法注意力
:param q_dim: Query 向量维度
:param k_dim: Key 向量维度
:param v_dim: Value 向量维度
:param out_dim: 输出向量维度
"""
super().__init__()
# 计算注意力分数:q + k 拼接 → 线性层 → 得到分数
self.attn_score = nn.Linear(q_dim + k_dim, 1)
# 融合原始 query 和 注意力加权后的 value → 投影到输出
self.attn_combine = nn.Linear(q_dim + v_dim, out_dim)
def forward(self, q, k, v):
"""
前向传播
:param q: Query (batch, 1, q_dim) - 当前 Decoder 隐状态
:param k: Key (batch, seq_len, k_dim) - Encoder 所有时刻输出
:param v: Value (batch, seq_len, v_dim) - Encoder 所有时刻输出
:return: (output, attention_weights)
"""
batch_size = q.size(0)
seq_len = k.size(1)
# 1. Query 扩展维度,让每个 Key 都能拼一次 Query
# (batch, 1, q_dim) → (batch, seq_len, q_dim)
q_expanded = q.expand(batch_size, seq_len, -1)
# 2. 拼接 Query 和 Key → 计算注意力分数
# (batch, seq_len, q_dim + k_dim)
qk_cat = torch.cat((q_expanded, k), dim=-1)
# 线性层计算分数 → (batch, seq_len, 1) → (batch, seq_len)
attn_scores = self.attn_score(qk_cat).squeeze(-1)
# 3. softmax 归一化得到注意力权重 [0, 1]
attn_weights = F.softmax(attn_scores, dim=-1) # (batch, seq_len)
# 4. 加权求和得到上下文向量
# (batch, 1, seq_len) @ (batch, seq_len, v_dim) = (batch, 1, v_dim)
context = torch.bmm(attn_weights.unsqueeze(1), v)
# 5. 拼接原始 Query 和上下文 → 投影到输出
# (batch, 1, q_dim + v_dim)
combined = torch.cat((q, context), dim=-1)
output = torch.tanh(self.attn_combine(combined)) # (batch, 1, out_dim)
return output, attn_weights
维度变化流程:
| 步骤 | 输入维度 | 输出维度 |
|---|---|---|
| 输入 q | (batch, 1, q_dim) |
- |
| 输入 k/v | (batch, seq_len, k_dim) / (batch, seq_len, v_dim) |
- |
| q 扩展 | (batch, 1, q_dim) → (batch, seq_len, q_dim) |
- |
| 拼接 q+k | - → (batch, seq_len, q_dim+k_dim) |
- |
| 计算分数 | (batch, seq_len, q_dim+k_dim) → (batch, seq_len) |
每个位置一个分数 |
| softmax | (batch, seq_len) → (batch, seq_len) |
归一化为概率 |
| 加权求和 | (batch, 1, seq_len) @ (batch, seq_len, v_dim) → (batch, 1, v_dim) |
上下文向量 |
| 拼接+输出 | cat(q, context) → 线性 → (batch, 1, out_dim) |
最终输出 |
针对 单个 Query + 单个 Key 场景(RNN Decoder 单步解码)的简洁实现,Query 和 Key 拼接后直接输出所有 Value 位置的分数。
import torch
import torch.nn as nn
import torch.nn.functional as F
class MyAttention(nn.Module):
def __init__(self, q_size, k_size, v_len, v_size, out_size):
"""
初始化自定义注意力
:param q_size: 查询张量 q 的维度
:param k_size: 键张量 k 的维度
:param v_len: 值张量 v 的序列长度
:param v_size: 值张量 v 的维度
:param out_size: 输出张量维度
"""
super().__init__()
self.q_size = q_size
self.k_size = k_size
self.v_len = v_len
self.v_size = v_size
self.out_size = out_size
# 1. q + k 拼接 → 直接输出 v_len 个位置的注意力分数
self.attn = nn.Linear(self.q_size + self.k_size, self.v_len)
# 2. 融合 q 和 加权后的 context → 投影到输出
self.attn_combine = nn.Linear(self.q_size + self.v_size, self.out_size)
def forward(self, q, k, v):
"""
前向传播
:param q: 查询张量 (1, 1, q_size) -> batch=1, seq_len=1
:param k: 键向量 (1, 1, k_size) -> batch=1, seq_len=1
:param v: 值向量 (1, v_len, v_size) -> Encoder 所有输出
:return: (output, attention_weights)
"""
# 1. q 和 k 拼接 → (1, q_size + k_size)
qk_cat = torch.cat((q[0], k[0]), dim=-1)
# 2. 线性层直接输出 v_len 个分数 → (1, v_len)
attn_scores = self.attn(qk_cat)
# 3. softmax 归一化得到注意力权重 → (1, v_len)
attn_weights = F.softmax(attn_scores, dim=-1)
# 4. 扩展维度 → (1, 1, v_len),然后 bmm 加权求和
# (1, 1, v_len) @ (1, v_len, v_size) = (1, 1, v_size)
attn_weights = attn_weights.unsqueeze(0)
context = torch.bmm(attn_weights, v)
# 5. 融合原始 q 和上下文 → 投影输出
# (1, 1, q_size + v_size) → (1, 1, out_size)
out_cat = torch.cat((q, context), dim=-1)
output = self.attn_combine(out_cat)
return output, attn_weights.squeeze(0)
核心思路:
- 因为 q 和 k 都只有一个(当前 Decoder 步),直接拼接一次即可
- 线性层输出维度就是
v_len,每个输出对应 value 序列一个位置的分数 - 相比批量版代码更简洁,适合单步解码场景
维度变化:
| 步骤 | 维度变化 |
|---|---|
| q + k 拼接 | (1, 1, q_size) + (1, 1, k_size) → (1, q_size+k_size) |
| 计算分数 | (1, q_size+k_size) → (1, v_len) |
| softmax | 维度不变,归一化概率 |
| 加权求和 | (1, 1, v_len) @ (1, v_len, v_size) → (1, 1, v_size) |
| 拼接输出 | cat(q, context) → (1, 1, q_size+v_size) → 线性 → (1, 1, out_size) |
缩放点积自注意力 是 Transformer 使用的标准实现,相比加法注意力可以一次性矩阵乘法完成计算,效率更高。
import torch
import torch.nn as nn
import torch.nn.functional as F
class ScaledDotProductSelfAttention(nn.Module):
def __init__(self, embed_dim):
"""
初始化缩放点积自注意力
:param embed_dim: 输入输出嵌入维度
"""
super().__init__()
self.embed_dim = embed_dim
# Q、K、V 三个投影矩阵
self.W_q = nn.Linear(embed_dim, embed_dim)
self.W_k = nn.Linear(embed_dim, embed_dim)
self.W_v = nn.Linear(embed_dim, embed_dim)
def forward(self, x, mask=None):
"""
前向传播
:param x: 输入序列 (batch_size, seq_len, embed_dim)
:param mask: 可选掩码,True 表示需要 mask 掉该位置
:return: (output, attention_weights)
"""
batch_size, seq_len, _ = x.shape
# 1. 对每个 token 投影得到 Q、K、V
q = self.W_q(x) # (batch, seq_len, embed_dim)
k = self.W_k(x) # (batch, seq_len, embed_dim)
v = self.W_v(x) # (batch, seq_len, embed_dim)
# 2. 计算注意力分数: (Q @ K^T) / sqrt(d_k)
# (batch, seq_len, embed_dim) @ (batch, embed_dim, seq_len) = (batch, seq_len, seq_len)
scores = torch.bmm(q, k.transpose(1, 2)) / torch.sqrt(torch.tensor(self.embed_dim))
# 3. 如果有掩码,把对应位置设为 -inf
if mask is not None:
# mask shape: (batch, seq_len), True = 需要 mask
scores = scores.masked_fill(mask.unsqueeze(1), -float('inf'))
# 4. softmax 归一化得到注意力权重
attn_weights = F.softmax(scores, dim=-1) # (batch, seq_len, seq_len)
# 5. 加权求和得到输出
# (batch, seq_len, seq_len) @ (batch, seq_len, embed_dim) = (batch, seq_len, embed_dim)
output = torch.bmm(attn_weights, v)
return output, attn_weights
使用示例:
# batch_size=2, seq_len=5, embed_dim=128
batch_size, seq_len, embed_dim = 2, 5, 128
x = torch.randn(batch_size, seq_len, embed_dim)
self_attn = ScaledDotProductSelfAttention(embed_dim)
output, attn = self_attn(x)
print(f"输入形状: {x.shape}") # torch.Size([2, 5, 128])
print(f"输出形状: {output.shape}") # torch.Size([2, 5, 128])
print(f"注意力权重形状: {attn.shape}") # torch.Size([2, 5, 5])
掩码自注意力 用在 Transformer Decoder 中,保证每个位置只能看到它前面的位置,不能看到未来信息。在缩放点积自注意力基础上加上下三角掩码即可:
class MaskedScaledDotProductSelfAttention(nn.Module):
def __init__(self, embed_dim):
super().__init__()
self.embed_dim = embed_dim
self.W_q = nn.Linear(embed_dim, embed_dim)
self.W_k = nn.Linear(embed_dim, embed_dim)
self.W_v = nn.Linear(embed_dim, embed_dim)
def forward(self, x):
batch_size, seq_len, embed_dim = x.shape
q = self.W_q(x)
k = self.W_k(x)
v = self.W_v(x)
scores = torch.bmm(q, k.transpose(1, 2)) / torch.sqrt(torch.tensor(self.embed_dim))
# === 生成下三角掩码 ===
# 只保留当前位置及之前的位置,未来位置 mask 掉
mask = torch.tril(torch.ones(seq_len, seq_len, device=x.device)).bool()
scores = scores.masked_fill(~mask, -float('inf'))
attn_weights = F.softmax(scores, dim=-1)
output = torch.bmm(attn_weights, v)
return output, attn_weights
两种注意力对比:
| 对比维度 | Bahdanau 加法注意力 | 缩放点积注意力 |
|---|---|---|
| 适用场景 | 传统 RNN Encoder-Decoder | Transformer |
| 计算方式 | 每个 Key 拼接 Query → 线性层算分数 | Q 点积 K^T → 直接算分数 |
| 复杂度 | 逐位置计算 | 矩阵乘法一次性完成 |
| 效率 | 较慢 | 更快,支持全并行 |
| 使用地方 | 传统 NMT 解码器 | 现代Transformer 编码器/解码器 |
NLP Transformer ⭐⭐⭐🚀
1. Transformer 概述
Transformer 是 Google 在 2017 年论文 Attention Is All You Need 中提出的完全基于自注意力机制的序列建模框架,彻底抛弃了传统 RNN/CNN 的循环结构,实现了全并行计算,成为了现代大语言模型的基础架构。
论文核心观点
循环神经网络(RNN、LSTM)固有的顺序计算特性阻碍了训练过程中的并行化,限制了模型能处理的序列长度。注意力机制可以实现并行计算,同时能更好地建模长距离依赖。
2. Transformer 整体架构
Transformer 采用 Encoder-Decoder 结构:
![]()
输入部分: 包含原文本和目标文本的嵌入层和位置编码器 输出部分: 线性层 + softmax 编码器部分:由 N 个编码器层堆叠而成,每个编码器层又由两个子层构成,第一个子层连接结构包括一个多头自注意力机制、归一化和残差连接层,第二个子层连接结构包括一个前馈全连接层、归一化和残差连接层。 解码器部分:
3. 核心设计思路
为什么需要位置编码?
自注意力机制本身是无序的——它只计算加权求和,不考虑 Q/K/V 的顺序。如果不加入位置信息,模型会把 "我爱你" 和 "你爱我" 当成相同的序列。
常见位置编码方案:
| 位置编码方式 | 特点 | 使用 |
|---|---|---|
| 正弦余弦固定编码 | 公式计算,无需学习,可推广到更长序列 | 原始 Transformer |
| 可学习位置嵌入 | 每个位置学习一个向量,灵活 | BERT、GPT 系列 |
| 旋转位置编码 RoPE | 为 Q/K 加入旋转角度,相对位置编码 | LLaMA、ChatGLM |
| ALiBi | 不编码位置,直接在注意力分数加偏置 | 可推广到超长序列 |
原始 Transformer 使用正弦余弦位置编码,公式:
其中 pos 是位置,i 是维度索引,d_model 是模型维度。
为什么要缩放点积?
当 d_k 较大时,Q·K^T 的方差会变大,导致 softmax 输出进入饱和区(梯度极小)。除以 √d_k 可以保持方差为 1,让训练更稳定。
为什么需要多头注意力?
多头注意力(Multi-Head Attention) 把 Q/K/V 投影到多个不同的子空间,每个头学习不同类型的注意力依赖:
- 某些头学习句法依赖
- 某些头学习共指关系
- 某些头学习长距离语义关联
多个头的输出最后拼接再投影,得到最终结果。
4. Encoder vs Decoder
作用:将输入序列编码为上下文感知的向量表示
结构:N 个相同层堆叠,每层包含: 1. 多头自注意力(所有位置可见) 2. 残差连接 + LayerNorm 3. 前馈网络(两层线性 + 激活) 4. 残差连接 + LayerNorm
输出:每个位置都融合了整个序列的上下文信息
使用场景: - BERT 就是只有 Encoder,用于理解任务(分类、填空) - 给 Decoder 提供编码结果
作用:自回归生成输出序列
结构:N 个相同层堆叠,每层包含三个子层: 1. 带掩码的多头自注意力(只能看到当前及之前位置) 2. 残差连接 + LayerNorm 3. Encoder-Decoder 交叉注意力(Q 来自 Decoder,K/V 来自 Encoder) 4. 残差连接 + LayerNorm 5. 前馈网络 6. 残差连接 + LayerNorm
输出:下一个 token 的概率分布
使用场景: - GPT 就是只有 Decoder,用于生成任务 - 原始 Transformer 机器翻译:Encoder 读源语言,Decoder 生成目标语言
5 Transformer 关键创新点
- 完全基于注意力:彻底摆脱 RNN,实现全并行训练,大幅提速
- 位置编码显式注入位置信息:解决注意力无序问题
- 缩放点积注意力:数值稳定且计算高效
- 多头注意力:多子空间并行学习不同依赖
- 残差+LayerNorm:让深层网络能够稳定训练
对后续工作的影响
Transformer 的出现彻底改变了 NLP 领域: - BERT(Encoder-only):双向语言模型,预训练+微调范式 - GPT(Decoder-only):自回归预训练,催生了现代大语言模型 - T5(Encoder-Decoder):统一所有 NLP 任务为文本到文本格式 - 几乎所有现代大语言模型都基于 Transformer Decoder 架构
6 关键超参数(原始 Transformer 论文)
| 超参数 | 值 | 说明 |
|---|---|---|
d_model |
512 | 模型维度,所有残差投影都回到这个维度 |
d_ff |
2048 | 前馈网络中间层维度 |
h (heads) |
8 | 多头注意力的头数 |
N (layers) |
6 | Encoder/Decoder 层数 |
batch_size |
4096 | 训练批量大小(词数) |
dropout |
0.1 | Dropout 概率 |
learning_rate |
0.0001 | 学习率 |