LangGraph
LangGraph 概述
LangGraph 是什么?
LangGraph is very low-level, and focused entirely on agent orchestration.
LangGraph 与 LangChain
LangChain 的 Chain 天然是顺序执行的(DAG),即使有分支链也难以处理复杂编排;而 Agent 虽能实现 ReAct 模式,但执行过程是黑盒,无法精细干预。
为解决这些局限,LangGraph 应运而生——它专注于 Agent 编排(orchestration),提供循环图、状态管理、人工介入等底层能力,让我们尽可能的掌控 Agent 的执行流程。
LangGraph 核心优势
LangGraph is focused on the underlying capabilities important for agent orchestration: durable execution, streaming, human-in-the-loop, and more.
- Durable execution:故障恢复、断点续跑、长时间运行
- Human-in-the-loop:随时检查和修改 Agent 状态
- Comprehensive memory:短期推理记忆 + 跨会话长期记忆
- Debugging with LangSmith:可视化追踪、状态转换、运行时指标
- Production-ready deployment::专为有状态工作流设计的可扩展架构
LangGraph 的实用场景
LangChain 适合流程固定、逻辑简单的场景;LangGraph 适用于:
- 多轮对话 Agent:需维护对话状态和上下文记忆
- 复杂工作流:循环执行、条件分支、动态路由
- 人工审核流程:关键节点需人工确认或修改
- 长期运行任务:需故障恢复、断点续跑
- Multi-Agent 协作:多 Agent 间有依赖或通信
一句话:需要精细控制流程、维护状态、人工介入时,选 LangGraph。
LangGraph HelloWorld
这个案例不涉及 Agent、ChatModel,只展示 LangGraph 核心概念。从案例可看出:Graph 的输入是一个 State 字典,每个节点接收上一节点返回的 State 更新,并返回部分更新合并到 State 中。
更多可参考:官方入门案例
from langgraph.graph import StateGraph
from langgraph.constants import START, END
from typing import TypedDict
# 定义共享状态
class HelloState(TypedDict):
name: str
# 定义节点(函数)
def hello(state: HelloState) -> HelloState:
return {
"name": f"Hello, {state['name']}!"
}
def add_emoji(state: HelloState) -> HelloState:
return {
"name": f"{state['name']} 😊"
}
# 创建图
graph = StateGraph(HelloState)
# 添加节点
graph.add_node('hello', hello)
graph.add_node('add_emoji', add_emoji)
# 添加边
graph.add_edge(START, 'hello')
graph.add_edge('hello', 'add_emoji')
graph.add_edge('add_emoji', END)
# 编译图
app = graph.compile()
resp = app.invoke({"name": "liutianba7"})
print(resp)
LangGraph 核心概念
State
State 是图中各节点共享的数据结构,贯穿整个执行流程。
from typing import TypedDict, Annotated
from langgraph.graph import add_messages
# 基础定义
class State(TypedDict):
name: str
count: int
# 使用 Annotated + Reducer(自动合并)
class State(TypedDict):
messages: Annotated[list, add_messages] # 自动追加消息
- State 通过
TypedDict定义类型 - 节点返回部分更新,自动合并到 State 中
Annotated[type, reducer]可指定合并策略(如add_messages追加消息)
Node
节点是图中的处理单元,本质上是一个函数。
def my_node(state: State) -> dict:
# 读取 state
name = state["name"]
# 返回部分更新
return {"name": f"Hello, {name}"}
- 输入:当前 State
- 输出:State 的部分更新
- 函数名即节点名,或通过
add_node('name', func)指定
Edge
边定义节点之间的执行顺序和条件。
普通边:固定跳转
条件边:动态路由
def route_fn(state: State) -> str:
return 'node_b' if state['count'] > 5 else 'node_c'
graph.add_conditional_edges('node_a', route_fn)
Graph
图的构建流程:定义 State → 添加节点 → 添加边 → 编译执行
from langgraph.graph import StateGraph, START, END
# 1. 创建图
graph = StateGraph(State)
# 2. 添加节点
graph.add_node('node_a', node_a_func)
graph.add_node('node_b', node_b_func)
# 3. 添加边
graph.add_edge(START, 'node_a')
graph.add_edge('node_a', 'node_b')
graph.add_edge('node_b', END)
# 4. 编译
app = graph.compile()
# 5. 执行
result = app.invoke({"name": "test"})
LangGraph 图的构建
StateGraph(state_schema)— 创建图add_node(name, func)— 添加节点add_edge(from, to)— 添加普通边add_conditional_edges(from, route_fn)— 添加条件边set_entry_point(name)— 设置入口节点set_conditional_entry_point(route_fn)— 条件入口compile()— 编译图
LangGraph State
State 是什么?
State: A shared data structure that represents the current snapshot of your application. It can be any data type, but is typically defined using a shared state schema.
State 定义方式
LangGraph 支持使用 TypedDict 、dataclass、Pydantic BaseModel去定义 State。
注意
LangChain 的 create_agent 工厂函数不支持 Pydantic State 定义
TypedDict
Dataclass
如何 State 需要默认值,则使用 dataclass 定义 State
@dataclass
class StateWithDefaults:
messages: list = field(default_factory=list) # 默认空列表
retries: int = 3 # 默认值
status: str = "pending"
Pydantic
如果需要做参数校验,则使用 pydantic 这种方式定义 State
class PydanticState(BaseModel):
name: str = Field(..., description='name', max_length=10)
age: int = Field(..., description='age', gt=0)
State Multiple schemas
通常所有节点共享同一个 State Schema,但有时需要更精细的控制:
- 内部节点传递的信息不需要出现在图的输入/输出中
- 图的输入/输出 Schema 与内部 Schema 不同
- 输出只包含少数关键字段
Private State(私有状态) :定义私有 Schema,用于内部节点通信,不会暴露给图的输入/输出:
Input / Output Schema :定义显式的输入、输出 Schema,约束图的输入和输出:
class InputState(TypedDict):
user_input: str
class OutputState(TypedDict):
graph_output: str
class OverallState(TypedDict):
foo: str
user_input: str
graph_output: str
# 创建图时指定 input/output schema
builder = StateGraph(OverallState, input_schema=InputState, output_schema=OutputState)
关键细节
- 图的 State 是所有定义 Schema 的合集。
- 节点可写入图中定义过的 state channel:即使节点输入 Schema 不包含某字段,节点仍可写入图中定义的其他 state channel(如
node_1写入foo) - 节点可声明新的 state channel:只要 Schema 定义存在,节点就能使用未在
StateGraph初始化中传入的 Schema(如PrivateState)
总结
- 写入:只要字段在图的某个 Schema 中定义过,节点就能写
- 新增:只要 Schema 类定义存在,节点就能用它,LangGraph 自动注册
State Reducer
在 LangGraph 中,描述 State 每个键如何被更新的函数就是 Reducer,State 中的每个键都会对应一个 Reducer。
Reducer 默认行为
不指定 Reducer 时,默认直接覆盖:
class AgentState(TypedDict):
name: str # 默认 Reducer 是覆盖
messages: Annotated[list[AnyMessage]] # 默认 Reducer 是覆盖
Reducer 内置
使用 Annotated[type, reducer] 指定合并策略:
from operator import add
# 定义整个图的 State Schemaclass AgentState(TypedDict):
name: Annotated[str, operator.add] # 追加策略
messages: Annotated[list[AnyMessage], operator.add] # 追加策略
operator.add— 列表追加、数值累加add_messages— 消息追加(LangGraph 内置)merge_dicts— 字典合并
Reducer 自定义
编写自己的合并函数,接收 (current_value, new_value) 返回合并结果:
def custom_reducer(current: list, new: list) -> list:
"""自定义合并逻辑:去重合并"""
return current + [x for x in new if x not in current]
class State(TypedDict):
items: Annotated[list[str], custom_reducer]
# 输入:{"items": ["a", "b"]}
# Node 返回 {"items": ["b", "c"]}
# 结果:{"items": ["a", "b", "c"]} ← b 已存在,不重复添加
Reducer 函数签名
reducer(current_value, new_value) -> merged_value
Reducer 强制覆盖
某些场景需要绕过 Reducer 直接覆盖,使用 Overwrite 类型:
from langgraph.graph import Overwrite
# 假设 bar 配置了追加策略
class State(TypedDict):
bar: Annotated[list[str], add]
# 但某节点想强制覆盖而非追加
def force_overwrite_node(state: State):
return {"bar": Overwrite(["new_value"])} # 直接覆盖,绕过 add reducer
使用场景
In some cases, you may want to bypass a reducer and directly overwrite a state value. LangGraph provides the Overwrite type for this purpose. Learn how to use Overwrite here.
Reducer State 初始值陷阱
问题:LangGraph 会为 State 字段赋予初始值,我们传入的值本质上是覆盖了原有的初始值。但是对于非覆盖 Reducer(如 operator.mul)来说,就会出现一些问题。
class AgentState(TypedDict):
age: Annotated[float, operator.mul] # float 默认值是 0.0
app.invoke({'age': 1}) # 结果:age = 0.0 ❌
# 原因:0.0 * 1 = 0.0
解决方案:
- 方案 1:不用 Annotated,直接
age: float,节点返回什么就是什么 - 方案 2:使用
Overwrite(1)包裹初始值,避免与默认值进行 reducer 操作 - 方案 3:使用自定义
Reducer
累加型 reducer(operator.add)没问题(0 + x = x),但累乘型(operator.mul)会得到 0(0.0 * x = 0.0),必须特殊处理这个初始值。
LangGraph Node
Node 概述
Nodes是编码 Agent 逻辑的 Python 函数(同步或异步),接收当前 State,执行计算或副作用,返回更新后的 State。Node 函数的参数如下:
state—The state of the graphconfig—ARunnableConfigobject that contains configuration information likethread_idand tracing information liketagsruntime—ARuntimeobject that contains runtimecontextand other information likestore,stream_writer, andexecution_info
Node 定义方式
基础节点:只接收 state
带 config 的节点:
def node_with_config(state: State, config: RunnableConfig):
thread_id = config["configurable"]["thread_id"]
return {"results": f"Hello, {state['input']}!"}
带 runtime 的节点:
def node_with_runtime(state: State, runtime: Runtime):
user_id = runtime.context.user_id # 获取运行时上下文
return {"results": f"Hello, {state['input']}!"}
幕后机制
函数会被转换为 RunnableLambda,自动获得 batch、async、tracing 支持
Node 特殊节点
START:入口节点,表示用户输入进入图的起点
END:终止节点,表示流程结束
Node 缓存
LangGraph 支持基于输入的节点缓存,相同输入再次执行时直接返回缓存值,无需重复计算。
使用缓存的步骤:
- 编译图时指定 cache
- 添加节点时指定
cache_policy
CachePolicy 参数:
| 参数 | 说明 |
|---|---|
key_func |
生成缓存 key 的函数,默认对输入做 pickle hash |
ttl |
缓存过期时间(秒),不指定则永不过期 |
示例:
from langgraph.cache.memory import InMemoryCache
from langgraph.types import CachePolicy
def expensive_node(state: State):
time.sleep(2) # 耗时计算
return {"result": state["x"] * 2}
# 添加节点时指定缓存策略
builder.add_node("expensive_node", expensive_node, cache_policy=CachePolicy(ttl=3))
# 编译时指定缓存
graph = builder.compile(cache=InMemoryCache())
# 第一次执行:耗时 2s
graph.invoke({"x": 5}) # {'result': 10}
# 第二次执行(3s 内):命中缓存,立即返回
graph.invoke({"x": 5}) # {'result': 10, '__metadata__': {'cached': True}}
适用场景
耗时计算节点(如 LLM 调用、数据处理),相同输入频繁执行时启用缓存可显著提升性能。
Node 异常重试
LangGraph 支持为节点配置重试策略,适用于 API 调用、数据库查询、LLM 调用等可能失败的操作。
基本用法:
from langgraph.types import RetryPolicy
builder.add_node("node_name", node_function, retry_policy=RetryPolicy())
| 参数 | 说明 |
|---|---|
max_attempts |
最大重试次数 |
retry_on |
触发重试的异常条件,默认使用 default_retry_on |
wait |
重试等待策略 |
retry_on
retry_on:List of exception classes that should trigger a retry, or a callable that returns True for exceptions that should trigger a retry.
默认重试策略:默认重试除了以下异常外的所有异常
ValueError、TypeError、ArithmeticErrorImportError、LookupError、NameErrorSyntaxError、RuntimeError、ReferenceErrorStopIteration、StopAsyncIteration、OSError
对于 HTTP 库(requests、httpx),仅对 5xx 状态码重试。
获取重试信息:通过 runtime.execution_info 可获取当前重试状态:
from langgraph.runtime import Runtime
def my_node(state: State, runtime: Runtime):
info = runtime.execution_info
if info.node_attempt > 1:
# 重试时使用备用方案
return {"result": call_fallback_api()}
return {"result": call_primary_api()}
builder.add_node("my_node", my_node, retry_policy=RetryPolicy(max_attempts=3))
execution_info 属性:
| 属性 | 说明 |
|---|---|
node_attempt |
当前执行尝试次数(1-indexed),首次为 1,重试时递增 |
node_first_attempt_time |
第一次尝试的 Unix 时间戳(秒),重试期间保持不变 |
适用场景
外部 API 调用、LLM 调用、数据库查询等不稳定操作,配置重试策略可提高可靠性。
LangGraph Edge
Edges define how the logic is routed and how the graph decides to stop. This is a big part of how your agents work and how different nodes communicate with each other. There are a few key types of edges:
Edge 类型
| 类型 | 说明 |
|---|---|
| Normal Edge | 固定从一个节点到下一个节点 |
| Conditional Edge | 调用函数决定下一步去哪个节点 |
| Entry Point | 用户输入进入图的第一个节点 |
| Conditional Entry Point | 调用函数决定第一个执行的节点 |
并行执行
一个节点可以有多个出边,所有目标节点将在下一个 superstep 中并行执行。
Normal Edge
固定路由,A → B:
Conditional Edge
动态路由,根据函数返回值决定下一个节点:
def routing_function(state: State) -> str:
return "node_b" if state["success"] else "node_c"
# 基本用法:返回值即为节点名
graph.add_conditional_edges("node_a", routing_function)
# 可选:映射返回值到节点名
graph.add_conditional_edges("node_a", routing_function, {True: "node_b", False: "node_c"})
Entry Point
图的入口,指定第一个执行的节点:
Conditional Entry Point
根据逻辑动态决定入口节点:
from langgraph.graph import START
graph.add_conditional_edges(START, routing_function)
graph.add_conditional_edges(START, routing_function, {True: "node_b", False: "node_c"})
Command 替代方案
如果想在同一个函数中同时更新状态和路由,可使用 Command 替代条件边。
LangGraph Send
默认情况下,节点和边在编译前就已定义,且所有节点共享同一个 State。但某些场景下:
- 边的数量预先未知(如动态生成的列表长度)
- 需要不同版本的 State 同时存在(如 Map-Reduce 模式)
Send 用于支持这种动态分发模式,从条件边返回 Send 对象,将不同 State 发送到同一节点。
Send 参数
| 参数 | 说明 |
|---|---|
node_name |
目标节点名称 |
state_dict |
传递给该节点的 State(可以是不同的 State) |
示例:Map-Reduce 模式
from langgraph.types import Send
def continue_to_jokes(state: OverallState):
# 动态生成多个 Send,每个 subject 发送到 generate_joke 节点
return [Send("generate_joke", {"subject": s}) for s in state['subjects']]
graph.add_conditional_edges("node_a", continue_to_jokes)
适用场景
Map-Reduce 模式:一个节点生成列表,后续节点并行处理列表中的每个元素(元素数量预先未知)。
LangGraph Command
Command 是一个灵活的原语,用于控制图的执行,支持状态更新和路由控制的组合。它接收下面这四个参数:
update: 应用状态更新(类似节点返回更新)goto: 跳转到指定节点(类似条件边)graph: 从子图跳转到父图的节点resume: 在中断后恢复执行,提供值
Command 被使用于下面这些场景:
- Return from nodes:使用
update+goto组合状态更新和控制流 - Input to
invoke/stream:使用resume在中断后恢复执行 - Return from tools:在 Tool 内更新状态并控制路由
Return from nodes
update and goto
Return Command from node functions to update state and route to the next node in a single step:
def my_node(state: State) -> Command[Literal["my_other_node"]]:
return Command(
# state update
update={"foo": "bar"},
# control flow
goto="my_other_node"
)
With Command you can also achieve dynamic control flow behavior (identical to conditional edges):
def my_node(state: State) -> Command[Literal["node_a", "node_b"]]:
if state["foo"] == "bar":
return Command(update={"foo": "baz"}, goto="node_a")
return Command(update={"foo": "qux"}, goto="node_b")
使用时机
需要同时更新状态和路由时用 Command;仅路由不更新状态时,用条件边即可。
类型注解要求
返回 Command 时必须添加类型注解:Command[Literal["node_name"]],用于图渲染和告知 LangGraph 可能的路由目标。
静态边仍生效
Command 只添加动态边,add_edge 定义静态边仍会执行。如 node_a 返回 Command(goto="x") 且有 add_edge("node_a", "node_b"),则 node_b 和 x 都会执行。
graph
使用 graph=Command.PARENT 从子图节点跳转到父图节点,这在多智能体切换场景非常的 useful
def my_node(state: State) -> Command[Literal["other_subgraph"]]:
return Command(
update={"foo": "bar"},
goto="other_subgraph", # 父图中的节点
graph=Command.PARENT
)
注意
更新父图和子图共享的 key 时,父图必须定义对应的 Reducer。
Input to invoke/stream
使用 Command(resume=...) 提供值并恢复中断后的执行:
# 1. 定义 Stateclass AgentState(TypedDict):
messages: Annotated[list[AnyMessage], operator.add]
# 2. 创建 checkpointer(必需!否则无法使用 Command(resume=...))
checkpointer = MemorySaver()
# 3. 定义节点 - 使用 interrupt() 中断执行
def node_a(state: AgentState) -> AgentState:
answer = interrupt('Do you approve?')
print(f'用户回答:{answer}')
if answer == 'yes':
return {'messages': [AIMessage(content='你同意了')]}
else:
return {'messages': [AIMessage(content='你拒绝了')]}
# 4. 构建图
graph = StateGraph(AgentState)
graph.add_node('node_a', node_a)
graph.set_entry_point('node_a')
graph.set_finish_point('node_a')
app = graph.compile(checkpointer=checkpointer)
# 5. 执行流程
config = {'configurable': {'thread_id': '1'}}
# 第一次执行:触发中断
print('=== 第一次执行(触发中断)===')
resp = app.invoke({'messages': [HumanMessage(content='111')]}, config=config)
print(f'中断前结果:{resp}')
# 第二次执行:恢复中断
print('\n=== 第二次执行(恢复中断)===')
resp = app.invoke(Command(resume='yes'), config=config)
print(f'恢复后结果:{resp}')
多轮对话不要用 Command 作为输入
Command 会从最新 checkpoint 恢复(非 __start__),可能导致图卡住。继续对话应传普通 dict:
Return from tools
Tool 内可返回 Command 更新状态并控制路由:
@tool
def my_tool(state: State) -> Command:
return Command(update={"saved": True}, goto="next_node")
静态边仍生效
Tool 内 goto 添加动态边,调用 Tool 的节点的静态边仍会执行。
LangGraph Runtime
创建图时可指定 context_schema,用于向节点传递不属于 State 的运行时信息(如模型名称、数据库连接等依赖项)。
context_schema 的定义
@dataclass
class ContextSchema:
llm_provider: str = "openai"
graph = StateGraph(State, context_schema=ContextSchema)
传递 context 到 graph
在任意节点或者条件边路由函数获得 context
from langgraph.runtime import Runtime
def node_a(state: State, runtime: Runtime[ContextSchema]):
llm = get_llm(runtime.context.llm_provider)
# ...
适用场景
传递不属于 State 的依赖项(如配置、连接、用户信息),避免污染 State 结构。
LangGraph RunnableConfig
Recursion Limit
限制图执行的最大步数,超过则抛出 GraphRecursionError。
- 默认限制:1000 步(v1.0.6+)
- 设置方式:
config={"recursion_limit": 5} - 注意:
recursion_limit是独立配置项,不放在configurable中
访问当前步数
通过 config["metadata"]["langgraph_step"] 获取当前执行步数:
def my_node(state: dict, config: RunnableConfig) -> dict:
current_step = config["metadata"]["langgraph_step"]
print(f"Currently on step: {current_step}")
return state
RemainingSteps(剩余步数追踪)
LangGraph 提供 RemainingSteps 管理值,自动追踪剩余步数,实现主动式递归处理:
from langgraph.managed import RemainingSteps
class State(TypedDict):
messages: Annotated[list, lambda x, y: x + y]
remaining_steps: RemainingSteps # 自动填充
def reasoning_node(state: State) -> dict:
remaining = state["remaining_steps"]
if remaining <= 2:
return {"messages": ["Approaching limit, wrapping up..."]}
return {"messages": ["thinking..."]}
主动式 vs 被动式处理
| 方式 | 检测时机 | 处理位置 | 控制流 |
|---|---|---|---|
| 主动式(RemainingSteps) | 达到限制前 | 图内路由 | 正常完成 |
| 被动式(catch GraphRecursionError) | 超过限制后 | 图外 try/catch | 图终止 |
主动式优势:优雅降级、保存中间状态、更好用户体验、图正常完成
被动式优势:实现简单、无需修改图逻辑、集中错误处理
其他可用 metadata
def inspect_metadata(state: dict, config: RunnableConfig) -> dict:
metadata = config["metadata"]
print(f"Step: {metadata['langgraph_step']}")
print(f"Node: {metadata['langgraph_node']}")
print(f"Triggers: {metadata['langgraph_triggers']}")
print(f"Path: {metadata['langgraph_path']}")
print(f"Checkpoint NS: {metadata['langgraph_checkpoint_ns']}")
return state
一句话总结
context 传递依赖项,config 控制 runtime 行为(如 recursion_limit),metadata 提供执行信息(如当前步数)。
LangGraph 高级特性
Streaming
LangGraph 提供流式输出能力,通过 stream() / astream() 方法实时返回执行更新,显著提升 LLM 应用的用户体验。
基础用法
for chunk in graph.stream(
{"topic": "ice cream"},
stream_mode=["updates", "custom"], # 可传多个模式
version="v2", # 推荐 v2 格式
):
if chunk["type"] == "updates":
for node_name, state in chunk["data"].items():
print(f"Node {node_name} updated: {state}")
elif chunk["type"] == "custom":
print(f"Status: {chunk['data']['status']}")
Stream Modes
| 模式 | 说明 |
|---|---|
values |
每步后的完整 State |
updates |
每步后的 State 更新(仅变化的字段) |
messages |
LLM token 级别流式输出 |
custom |
自定义数据流式输出(通过 get_stream_writer()) |
checkpoints |
Checkpoint 事件(需要 checkpointer) |
tasks |
任务开始/结束事件(需要 checkpointer) |
debug |
最全信息(checkpoints + tasks + 额外元数据) |
Graph State 流式
# updates:仅返回更新的字段
for chunk in graph.stream(inputs, stream_mode="updates", version="v2"):
if chunk["type"] == "updates":
for node_name, state in chunk["data"].items():
print(f"Node `{node_name}` updated: {state}")
# values:返回完整 State
for chunk in graph.stream(inputs, stream_mode="values", version="v2"):
if chunk["type"] == "values":
print(chunk["data"]) # 完整 state
LLM Tokens 流式
使用 messages 模式流式输出 LLM token,
for chunk in graph.stream(inputs, stream_mode="messages", version="v2"):
if chunk["type"] == "messages":
msg, metadata = chunk["data"]
if msg.content:
print(msg.content, end="", flush=True)
按 tags 过滤
model = init_chat_model(model="gpt-4", tags=["joke"])
# 只流式输出特定 tag 的 LLM
if metadata["tags"] == ["joke"]:
print(msg.content)
按 node 过滤:
Tip
messages 模式返回的数据任然遵循统一的格式,但是 data 对应的是一个二元组,而不再是一个字典了。
Custom 自定义流式
节点内使用 get_stream_writer() 发送自定义数据:
from langgraph.config import get_stream_writer
def my_node(state: State):
writer = get_stream_writer()
writer({"status": "processing...", "progress": 50})
return {"result": "done"}
# 消费自定义数据
for chunk in graph.stream(inputs, stream_mode="custom", version="v2"):
if chunk["type"] == "custom":
print(chunk["data"])
v2 输出格式
{
"type": "values" | "updates" | "messages" | "custom" | ...,
"ns": (), # 子图命名空间(根图为空元组)
"data": ..., # 实际数据
}
| 场景 | v1(默认) | v2(推荐) |
|---|---|---|
| 单模式 | 返回原始数据 | StreamPart dict |
| 多模式 | (mode, data) 元组 |
StreamPart,用 type 区分 |
| 子图 | (namespace, data) 元组 |
StreamPart,用 ns 区分 |
invoke() 返回 |
普通字典 | GraphOutput 对象 |
Subgraph 流式
设置 subgraphs=True 包含子图输出:
for chunk in graph.stream(
inputs,
subgraphs=True,
stream_mode="updates",
version="v2",
):
if chunk["ns"]:
print(f"Subgraph {chunk['ns']}: {chunk['data']}")
else:
print(f"Root: {chunk['data']}")
多模式组合
在多模式组合下,v2 版本的输出结构才能体现出优势,无论是什么类型,是单模式还是多模式,v2 版本的输出都一致!
for chunk in graph.stream(
inputs,
stream_mode=["updates", "messages", "custom"],
version="v2",
):
if chunk["type"] == "updates":
...
elif chunk["type"] == "messages":
...
elif chunk["type"] == "custom":
...
禁用特定 LLM 流式
使用建议
- 推荐使用
version="v2"获得统一格式 updates适合监控节点输出,messages适合实时展示 LLM 输出custom适合进度条、日志等自定义场景
CheckPointer
LangGraph 内置持久化层,通过 Checkpoint 保存图的执行状态。启用持久化后,每个执行步骤都会保存状态快照,从而实现了人工介入、对话记忆、时间旅行调试和故障恢复。
注意
Agent Server handles checkpointing automatically When using the Agent Server, you don't need to implement or configure checkpointers manually. The server handles all persistence infrastructure for you behind the scenes.
为什么需要持久化?
| 功能 | 说明 |
|---|---|
| Human-in-the-loop | 人工可检查、中断、审批图的执行步骤 |
| Memory | 跨对话保持记忆,后续消息可访问之前的 State |
| Time travel | 回放历史执行、查看/调试特定步骤、分支探索 |
| Fault tolerance | 节点失败后可从上一个成功的步骤恢复 |
| Pending writes | 超级步骤中部分节点成功时,恢复时不重跑已成功的节点 |
核心概念
Threads
每个 Checkpoint 关联一个唯一的 thread_id,作为存储和检索的主键。
必须指定 thread_id
没有 thread_id,Checkpointer 无法保存状态或在中断后恢复执行。
Checkpoints
Checkpoint 是某个时刻的 State 快照,每个 Super-step 边界都会创建一个。
SuperStep
Super-step 是 LangGraph 运行时的最小执行单元,可以将其理解为图的一次“逻辑滴答(Tick)”。在一个 Super-step 中,所有当前被触发且可以执行的节点会同时启动(支持并行执行)。只有当该步骤内所有的节点都运行完毕后,图才会跨越边界进入下一个 Super-step。这种机制确保了复杂图结构在执行过程中的有序性。
Checkpoint namespace
每个检查点都有 checkpoint_ns 字段,标记着这个检查点属于哪个图或者子图。
可以通过 RunnableConfig 对象去获得当前检查点的命名空间
from langchain_core.runnables import RunnableConfig
def my_node(state: State, config: RunnableConfig):
checkpoint_ns = config["configurable"]["checkpoint_ns"]
# "" for the parent graph, "node_name:uuid" for a subgraph
获取、更新状态
StateSnapshot 字段
| 字段 | 说明 |
|---|---|
values |
该 checkpoint 的 State 值 |
next |
下一步要执行的节点(空 () 表示图已完成) |
config |
包含 thread_id、checkpoint_ns、checkpoint_id |
metadata |
执行元数据(source、writes、step) |
created_at |
创建时间(ISO 8601) |
parent_config |
上一个 checkpoint 的配置 |
tasks |
待执行任务列表 |
Get State
获取状态的核心就是凭“号”查“快照”:你必须提供一个 thread_id(线程 ID)作为索引,通过 graph.get_state(config) 就能拿到该线程最新的 StateSnapshot(状态快照);如果带上特定的 checkpoint_id,还能精准提取历史某个瞬间的状态,这就是实现状态回溯的基础。
# 获取最新状态
config = {"configurable": {"thread_id": "1"}}
graph.get_state(config)
# 获取特定 checkpoint
config = {"configurable": {"thread_id": "1", "checkpoint_id": "..."}}
graph.get_state(config)
Get State History
通过调用 graph.get_state_history(config),可以获取特定线程下所有执行记录的完整清单。该方法返回一个包含多个 StateSnapshot(状态快照)对象的列表,反映了该线程经历过的每一个 Super-step。需要特别注意的是,这些检查点是按逆序排列的,即最新的状态排在列表的首位,方便你快速追溯最近一次的操作记录。
history = list(graph.get_state_history(config))
# 按时间倒序排列,最新的在最前面
# 查找特定 checkpoint
before_node_b = next(s for s in history if s.next == ("node_b",))
step_2 = next(s for s in history if s.metadata["step"] == 2)
Replay
从历史 checkpoint 恢复执行,checkpoint 之前的节点跳过(结果已保存),之后的节点重新执行:
# 从特定 checkpoint_id 恢复
config = {"configurable": {"thread_id": "1", "checkpoint_id": "..."}}
graph.invoke(None, config) # 会重新执行后续节点
Update State
通过 update_state 方法可以手动编辑图的状态,其核心逻辑是“增量更新而非直接覆盖” :每次更新都会产生一个全新的检查点,而不会修改历史记录。如果状态字段定义了 reducer 函数(如列表累加),更新的值会进行累积;否则才会被覆盖。
此外,通过 as_node 参数可以伪装更新来源,从而改变图的下一步走向,是实现干预和控制执行流的关键手段。
CheckPointer 实现线程内记忆
线程级持久化让 Agent 能够追踪多轮对话。
基本用法:
from langgraph.checkpoint.memory import InMemorySaver
checkpointer = InMemorySaver() # 创建一个检查点对象
graph = builder.compile(checkpointer=checkpointer) # 在编译图的时候指定检查点
# 同一 thread_id 的多次调用会保持记忆
graph.invoke(
{"messages": [{"role": "user", "content": "hi! i am Bob"}]},
{"configurable": {"thread_id": "1"}},
)
生产环境:使用数据库支持的 Checkpointer:
from langgraph.checkpoint.postgres import PostgresSaver
DB_URI = "postgresql://user:pass@localhost:5432/db"
with PostgresSaver.from_conn_string(DB_URI) as checkpointer:
graph = builder.compile(checkpointer=checkpointer)
子图中使用:只需在父图编译时传入 checkpointer,LangGraph 会自动传播到子图:
# 子图
subgraph = subgraph_builder.compile()
# 父图 - 只需在这里传入 checkpointer
builder.add_node("node_1", subgraph)
graph = builder.compile(checkpointer=InMemorySaver())
可用的 Checkpointer 实现
更多集成 参考官方文档
InMemorySaver:开发测试用PostgresSaver:生产推荐SqliteSaver:本地开发RedisSaver/MongoDBSaver:可选
Memory Store
Checkpointer 只能保存线程内的状态,Store 支持跨线程存储信息(如用户偏好)。
核心定位对比
- Checkpointer:绑定
thread_id,负责当前对话的"进度条"。 - Store:绑定
user_id,负责长期留存的"档案袋"。
基础存取
Store 使用元组(Tuple)作为命名空间(Namespace)来隔离不同用户或类别的数据。使用 put 存入数据,search 检索数据。
import uuid
from langgraph.store.memory import InMemoryStore
store = InMemoryStore()
namespace = ("user_123", "memories") # 格式:(用户ID, 分类名)
# 📥 写入记忆 (Put)
store.put(namespace, str(uuid.uuid4()), {"food_preference": "I like pizza"})
# 📤 读取记忆 (Search)
memories = store.search(namespace)
print(memories[-1].dict()) # 获取列表最后一条(即最新的一条)
语义搜索
给 Store 配置 Embedding 模型后,即可通过自然语言进行模糊搜索,打破精准查询的限制。
from langchain.embeddings import init_embeddings
# 初始化配置了向量模型的 Store
store = InMemoryStore(
index={
"embed": init_embeddings("openai:text-embedding-3-small"),
"dims": 1536,
"fields": ["food_preference", "$"] # 指定需要被向量化的字段
}
)
# 使用自然语言模糊搜索
memories = store.search(
namespace,
query="What does the user like to eat?", # 模糊匹配,无需精准包含关键字
limit=3
)
在 LangGraph 中使用
在图的节点函数中,LangGraph 会自动注入 Runtime 对象用于读写记忆库。执行图时,需同时挂载 Checkpointer 和 Store,并通过 context 传入当前用户信息。
异步读写注意
在异步节点(async def)中,必须使用异步方法 runtime.store.aput 和 runtime.store.asearch。
from dataclasses import dataclass
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.runtime import Runtime
@dataclass
class Context:
user_id: str
# 节点:写入记忆
async def update_memory(state: MessagesState, runtime: Runtime[Context]):
namespace = (runtime.context.user_id, "memories")
await runtime.store.aput(namespace, str(uuid.uuid4()), {"memory": "用户今天很烦躁"})
# 节点:读取记忆
async def call_model(state: MessagesState, runtime: Runtime[Context]):
namespace = (runtime.context.user_id, "memories")
memories = await runtime.store.asearch(
namespace,
query=state["messages"][-1].content, # 用用户的最新发言去匹配历史记忆
limit=3
)
info = "\n".join([d.value["memory"] for d in memories])
# ==========================================
# 图的编译与执行
# ==========================================
checkpointer = InMemorySaver()
store = InMemoryStore()
# 编译时同时挂载进度条和记忆库
graph = builder.compile(checkpointer=checkpointer, store=store)
config = {"configurable": {"thread_id": "1"}} # 区分会话
graph.invoke(
{"messages": [{"role": "user", "content": "hi"}]},
config,
context=Context(user_id="1") # 传入 Context 区分用户
)
Time-travel
基于 Checkpoint 实现,支持重放和分支两种模式。
Replay
从历史 checkpoint 恢复执行,checkpoint 之前的节点跳过,之后的节点重新执行:
# 获取历史记录
history = list(graph.get_state_history(config))
# 找到特定 checkpoint
before_joke = next(s for s in history if s.next == ("write_joke",))
# 从该 checkpoint 重放
result = graph.invoke(None, before_joke.config)
Fork
从历史 checkpoint 创建分支,修改状态后继续执行,原历史记录保持不变:
# 找到特定 checkpoint
before_joke = next(s for s in history if s.next == ("write_joke",))
# Fork:修改状态,创建分支
fork_config = graph.update_state(
before_joke.config,
values={"topic": "chickens"},
)
# 从分支继续执行
fork_result = graph.invoke(None, fork_config)
as_node 参数
update_state 时可指定 as_node,控制更新被视为来自哪个节点,影响下一步执行:
fork_config = graph.update_state(
before_joke.config,
values={"topic": "chickens"},
as_node="generate_topic", # 视为来自 generate_topic
)
# 执行从 generate_topic 的后继节点开始
Interrupt 与 Time-travel
图使用 interrupt() 时,时间旅行会重新触发中断:
# Replay 会重新触发 interrupt
replay_result = graph.invoke(None, before_ask.config)
# 暂停在 interrupt,等待新的 Command(resume=...)
# Fork 后也需要新的 resume
fork_config = graph.update_state(before_ask.config, {"value": ["forked"]})
fork_result = graph.invoke(None, fork_config)
# 暂停在 interrupt
graph.invoke(Command(resume="Bob"), fork_config) # 用新的答案恢复
多 interrupt 场景
# 图:ask_name -> ask_age -> final
# Fork 到 ask_name 之后、ask_age 之前
between = [s for s in history if s.next == ("ask_age",)][-1]
fork_config = graph.update_state(between.config, {"value": ["modified"]})
result = graph.invoke(None, fork_config)
# ask_name 结果保留,ask_age 暂停等待新答案
子图的 Time Travel
利用子图进行时间旅行取决于子图是否拥有自己的检查点。这决定了你可以进行时间旅行的检查点粒度。
| 模式 | 说明 |
|---|---|
| 继承 checkpointer(默认) | 子图作为单个 super-step,无法从子图内部 checkpoint 重放 |
| 子图自有 checkpointer | 子图每步都有 checkpoint,可从子图内部任意点重放 |
# 子图自有 checkpointer
subgraph = subgraph_builder.compile(checkpointer=True)
# 获取子图的 checkpoint
parent_state = graph.get_state(config, subgraphs=True)
sub_config = parent_state.tasks[0].state.config
# 从子图内部 fork
fork_config = graph.update_state(sub_config, {"value": ["forked"]})
Summary
Replay 从历史 checkpoint 重新执行;Fork 从历史 checkpoint 创建分支探索不同路径;两者都会重新执行后续节点和 interrupt。
Subgraphs
子图是作为节点嵌入另一个图中的图,适用于多 Agent 系统、代码复用、团队协作开发。
子图通信模式
添加子图时,需要定义父图和子图之间的通信方式:
| 模式 | 适用场景 | 说明 |
|---|---|---|
| 在节点内调用子图 | 父子图有不同的 State Schema(无共享 key) | 需编写包装函数,手动转换父子图 State |
| 将子图作为节点添加 | 父子图共享 State key | 直接将编译后的子图传给 add_node,无需包装函数 |
在节点内调用子图(不同 State Schema)
父子图状态独立,需手动转换:
class SubgraphState(TypedDict):
bar: str # 子图私有
class ParentState(TypedDict):
foo: str # 父图私有
def call_subgraph(state: ParentState):
# 父图 State → 子图 State
subgraph_output = subgraph.invoke({"bar": state["foo"]})
# 子图 State → 父图 State
return {"foo": subgraph_output["bar"]}
builder.add_node("node_1", call_subgraph)
Add a subgraph as a node
此时,子图可以看作是父图的一个节点,父子图共享 State(本质其实就是不同节点可以有不同的 State Schema,最终图的 Schema 是所有 Schema 的集合):
class SubgraphState(TypedDict):
foo: str # 与父图共享
bar: str # 子图私有
class ParentState(TypedDict):
foo: str # 与子图共享
# 子图直接作为节点
builder.add_node("node_2", subgraph)
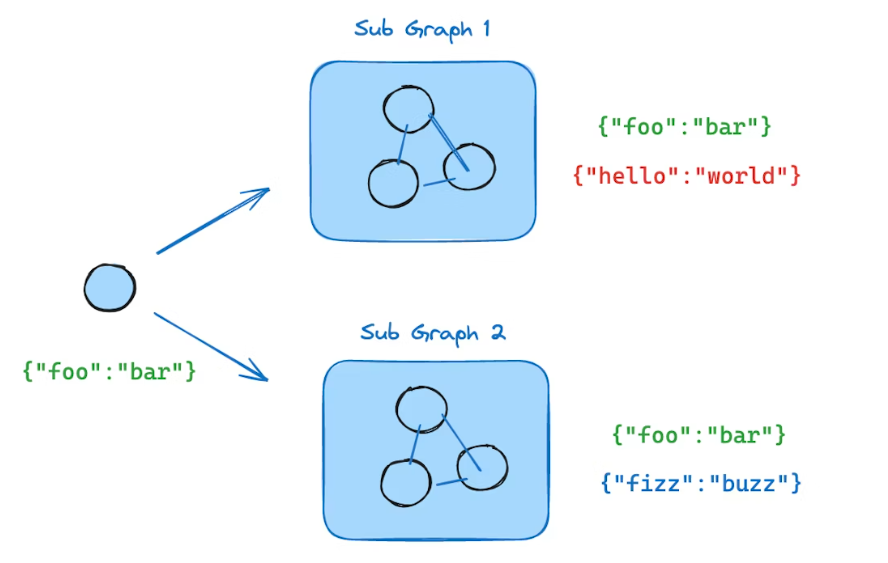
注意
子图可读取共享字段,也可写入共享字段;子图私有字段对外不可见。
子图持久化
通过 .compile(checkpointer=...) 控制子图的持久化行为:
| 模式 | checkpointer= |
说明 |
|---|---|---|
| Per-invocation(默认) | None |
每次调用重新开始,继承父图 checkpointer 支持 interrupt |
| Per-thread | True |
跨调用累积状态,同一线程每次调用接续上次 |
| Stateless | False |
无持久化,像普通函数调用,不支持 interrupt |
Per-invocation(默认)
推荐用于多 Agent 系统,子 Agent 不需要记忆历史:
fruit_agent = create_agent(
model="gpt-4",
tools=[fruit_info],
# checkpointer 不设置,默认 None
)
# 每次调用子图都是全新状态
agent.invoke({"messages": [...]}, config)
Per-thread
# 子图编译时设置 checkpointer=True
subgraph = subgraph_builder.compile(checkpointer=True)
# 同一 thread_id 的多次调用会累积状态
graph.invoke({"messages": [...]}, config) # 第一次
graph.invoke({"messages": [...]}, config) # 第二次,记住第一次的内容
Caution
Per-thread 模式下,同一子图不能在单次调用中并行执行多次。可用 ToolCallLimitMiddleware 限制。
Stateless
查看子图的 State
启用持久化后,可通过 subgraphs=True 查看子图状态:
流式输出子图事件
设置 subgraphs=True 获取子图的流式输出:
for chunk in graph.stream(
inputs,
subgraphs=True,
stream_mode="updates",
version="v2",
):
if chunk["ns"]:
print(f"Subgraph {chunk['ns']}: {chunk['data']}")
else:
print(f"Root: {chunk['data']}")
Multi Agent
多 Agent 系统协调多个专门化组件处理复杂工作流。
为什么需要多 Agent
| 需求 | 说明 |
|---|---|
| 上下文管理 | 提供专门知识而不压垮模型上下文窗口 |
| 分布式开发 | 不同团队独立开发和维护能力,组合成更大系统 |
| 并行化 | 生成专门化的 worker 并发执行子任务 |
适用场景:
- 单个 Agent 工具过多,决策困难
- 任务需要专门知识和大量上下文
- 需要顺序约束,某些能力仅在特定条件后解锁
多 Agent 模式
| 模式 | 工作方式 |
|---|---|
| Subagents(子代理) | 主 Agent 将子 Agent 作为工具协调,所有路由通过主 Agent |
| Handoffs(交接) | Agent 通过 Tool 调用转移控制权,动态切换 Agent |
| Skills(技能) | 单 Agent 按需加载专门化 prompt 和知识 |
| Router(路由器) | 路由步骤分类输入,分发给专门 Agent,合成结果 |
| Custom Workflow(自定义工作流) | 用 LangGraph 构建自定义执行流 |
Subagents 实现
官方推荐做法:将 Agent 调用包装为一个 tool,然后创建一个 Main Agent。还可以通过 langgraph-supervisor 来实现,但官方现在不推荐这个了。
from langchain.agents import create_agent
from langchain.tools import tool
# 1. 创建子 Agent
fruit_agent = create_agent(
model="gpt-4",
tools=[fruit_info],
prompt="You are a fruit expert.",
)
# 2. 将子 Agent 包装为 Tool
@tool
def ask_fruit_expert(question: str) -> str:
"""Ask the fruit expert. Use for ALL fruit questions."""
response = fruit_agent.invoke({"messages": [{"role": "user", "content": question}]})
return response["messages"][-1].content
# 3. 创建主 Agent,挂载子 Agent 作为 Tool
main_agent = create_agent(
model="gpt-4",
tools=[ask_fruit_expert],
prompt="You have a fruit expert. Delegate fruit questions to ask_fruit_expert.",
checkpointer=MemorySaver(),
)
执行流程:
特点:
- 主 Agent 作为唯一入口,统一调度
- 子 Agent 彼此隔离,各自维护独立上下文
- 每次调用子 Agent 都是从头开始(Per-invocation 默认行为)
- 支持并行调用多个不同的子 Agent
适用场景
多 Agent 协作,主 Agent 作为协调者,子 Agent 各司其职(如专家系统、多领域问答)。更多 multi-agent 的实现,可以参考 官方文档