FastApi
FastApi 的第一个程序
下载依赖(可以在 pychram 里面直接创建 fastapi 项目)
from fastapi import FastAPI
app = FastAPI()
@app.get("/")
async def root():
return {"message": "Hello World"}
@app.get("/hello/{name}")
async def say_hello(name: str):
return {"message": f"Hello {name}"}
启动 FastApi 项目
dev模式:它会自动开启 热重载 (Reload)。这意味着你改动代码并保存后,服务器会自动重启,不需要你手动重切命令行。- 交互式文档:启动后,它会提示你访问
http://127.0.0.1:8000/docs。
FastAPI 本身是一个 Web 框架,它需要一个“服务器守护进程”来运行,这个守护进程通常就是 Uvicorn。
main: 指的是你的文件名main.py。app: 指的是你在代码里创建的变量名app = FastAPI()。--reload: 关键参数!开启开发模式,代码变动即刻生效。
FastApi 入门
路由
路由的组成部分
- 路径 (Path):URL 中从第一个
/开始的部分(例如/items/1)。 - 操作 (Operation):对应的 HTTP 方法(GET, POST, PUT, DELETE 等)。
- 函数 (Function):被装饰的 Python 函数(通常被称为“路径操作函数”)。
简单来说,路由就是把用户访问的 URL 地址 映射到你写的 Python 函数上的过程。
@app.get("/hello") # 装饰器:定义方法(get)和路径(/hello)
async def say_hello(): # 函数:逻辑实现
return {"message": "你好,FastAPI"}
路由参数
如果想让 URL 的一部分变成变量,可以使用花括号 {}。FastAPI 会自动抓取这个值并传递给你的函数。
@app.get("/users/{user_id}")
async def get_user(user_id: int): # 这里的 : int 开启了自动类型校验
return {"user_id": user_id}
- 如果你访问
/users/10,结果是{"user_id": 10}。 - 如果你访问
/users/foo,FastAPI 会直接拦截并报错,因为它不是整数(int)。
路由的匹配是从上到下的。如果你有重叠的路径,请把更具体的写在前面:
@app.get("/users/me") # 具体的写在上面
async def read_user_me():
return {"user_id": "当前登录用户"}
@app.get("/users/{user_id}") # 通用的写在下面
async def read_user(user_id: str):
return {"user_id": user_id}
查询参数
当你的 URL 中出现 ? 时,后面的部分就是查询参数。在函数参数中定义不属于路径占位符的变量,FastAPI 会自动将其识别为查询参数。
@app.get("/items/")
async def read_items(skip: int = 0, limit: int = 10):
# 访问地址示例:/items/?skip=20&limit=50
return {"skip": skip, "limit": limit}
- 默认值:你可以像上面一样设置默认值(
0和10)。 - 可选参数:如果你想让某个参数可选,可以使用
Optional或设置默认值为None。
指定别名 (Alias)
有时候 Python 变量名不能有中划线(比如 user-name),但 API 规范要求用中划线。这时你可以用 alias:
from fastapi import Query
@app.get("/users/")
async def read_users(
user_id: str = Query(None, alias="user-id")
):
# 客户端访问时必须用 /users/?user-id=123
# 你的代码里用的是 user_id 变量
return {"user_id": user_id}
@app.get("/items/")
async def read_items(
q: str | None = Query(
default=None,
min_length=3, # 最小长度
max_length=50, # 最大长度
pattern="^fixedquery$" # 正则表达式
)
):
return {"q": q}
参数获取
路径参数 : 在路径中使用 {} 包裹变量名,并在函数参数中声明同名变量。
@app.get("/users/{user_id}")
async def get_user(user_id: int): # 自动转为 int 类型
return {"user_id": user_id}
查询参数 : URL 中 ? 后面的键值对。不需要在路径中声明,直接写在函数参数里即可。
@app.get("/items/")
async def read_items(page: int = 1, limit: Optional[int] = 10):
return {"page": page, "limit": limit}
请求体参数 : 通常用于 POST/PUT 请求,数据以 JSON 格式放在请求体中。使用继承自 BaseModel 的 Pydantic 模型作为参数类型。
from pydantic import BaseModel
class UserIn(BaseModel):
username: str
password: str
@app.post("/register")
async def register(user: UserIn): # FastAPI 会自动解析 JSON 为对象
return user
请求头参数 : 必须显式使用 Header 类,否则会被误认为查询参数。
async def get_user(
token: str=Header(None, alias="Authorization")
# request: Request # 也可以获得整个请求, 然后再去拿到请求头
参数校验
| 参数 | 说明 | 示例 |
|---|---|---|
gt / ge |
大于 / 大于等于 | ge=0 |
lt / le |
小于 / 小于等于 | le=100 |
min_length |
最小长度(字符串/列表) | min_length=3 |
max_length |
最大长度(字符串/列表) | max_length=50 |
pattern |
正则表达式匹配 | pattern="^abc" |
路径参数校验 Path()
from fastapi import FastAPI, Path
app = FastAPI()
@app.get("/items/{item_id}")
async def read_items(
# 使用 Path 而不是 Query
item_id: int = Path(..., title="项目的ID", ge=1, le=1000)
):
return {"item_id": item_id}
参数列表里的 * 代表后面的参数必须以“关键字参数”形式调用。虽然在 FastAPI 函数里不是必须的,但在复杂函数中这是一种规范写法。
在 Path(..., ...) 中,第一个参数 ... (Ellipsis) 表示该参数是必填的。在路径参数中,它本身就是必填的,但写上它是为了符合 FastAPI 的装饰器语法规范,方便后面跟上 gt 等校验参数。
查询参数 Query
pass
请求体参数
首先,你需要定义一个继承自 BaseModel 的类。这个类描述了你期望收到的 JSON 数据的结构。
from fastapi import FastAPI
from pydantic import BaseModel, Field
app = FastAPI()
# 定义数据模型
class Book(BaseModel):
title: str
author: str
price: float
is_published: bool | None = None # 可选字段,默认值为 None
@app.post("/books/")
async def create_book(book: Book): # FastAPI 看到 Book 模型,自动识别为 Request Body
return {"message": "书籍已创建", "data": book}
- 数据解析:它会自动把前端传来的 JSON 字符串转换成 Python 对象。你可以通过
book.title直接访问,而不是book["title"]。 - 自动校验:如果前端传的
price是字符串"abc",FastAPI 会直接拦截并报错。
就像 Path 和 Query 一样,Pydantic 提供了 Field 来对类内部的字段进行精细化校验。
class Book(BaseModel):
# title 必须是字符串,最小长度 2,最大长度 20
title: str = Field(..., min_length=2, max_length=20, title="书名")
# price 必须大于 0
price: float = Field(..., gt=0, description="价格必须大于零")
# 还可以限制列表长度、正则匹配等
tags: list[str] = Field(default=[], max_items=3)
响应知识点
在 FastAPI 中,响应不仅仅是 return 一个字典,它还涉及到数据过滤、状态码设置和性能优化。
响应模型 (Response Model)——最重要的知识点
这是 FastAPI 的杀手锏。通过在路径操作装饰器中添加 response_model 参数,你可以:
- 过滤敏感数据:比如用户模型里有密码,但在接口返回时自动剔除。
- 数据转换:自动将 Python 对象(如数据库模型)转换为符合定义的 JSON。
- 自动校验:确保你的 API 返回的数据确实符合你承诺的结构。
from pydantic import BaseModel, EmailStr
class UserIn(BaseModel):
username: str
password: str # 输入时需要密码
email: EmailStr
class UserOut(BaseModel):
username: str
email: EmailStr # 响应时不包含密码
@app.post("/user/", response_model=UserOut)
async def create_user(user: UserIn):
# 虽然你接收了带密码的数据,但由于指定了 UserOut
# FastAPI 会自动帮你把 password 字段过滤掉
return user
响应状态码 (Status Codes)
在 RESTful 风格中,正确的状态码是 API 的灵魂。
- 默认:成功通常返回
200 OK。 - 创建成功:通常应该返回
201 Created。
from fastapi import status
@app.post("/items/", status_code=status.HTTP_201_CREATED)
async def create_item(name: str):
return {"name": name}
响应类型
FastAPI 默认会把你的返回值塞进 JSONResponse 里。但有时候你不需要 JSON,比如:
- 你想直接返回一个 HTML 网页。
- 你想返回一段 纯文本。
- 你想返回一个 XML 或者 重定向。
设置了 response_class 后,FastAPI 会自动帮你设置正确的 Content-Type 响应头,并进行相应的初步处理。
| 响应类 | 用途 | Content-Type | |
|---|---|---|---|
JSONResponse (默认) |
返回 JSON 数据 | application/json |
|
HTMLResponse |
返回 HTML 字符串 | text/html; charset=utf-8 |
|
PlainTextResponse |
返回原始文本 | text/plain; charset=utf-8 |
|
RedirectResponse |
让浏览器跳转 URL | 不固定(状态码 3xx) | |
FileResponse |
异步传输文件(下载) | 自动根据扩展名识别 |
@app.get('/html', response_class=HTMLResponse)
async def get_html():
return HTMLResponse("<h1>Hello</h1>")
@app.get('/file')
async def get_file():
file_path = 'E:\\01_Images\\02_avatar\\01.jpg'
return FileResponse(file_path)
异常处理
基础语法
Python 使用 try...except 代码块来捕获并处理错误,防止程序崩溃。
try:
# 1. 尝试执行可能会报错的代码
result = 10 / 0
except ZeroDivisionError as e:
# 2. 捕获特定的异常并处理
print(f"错误发生了:{e}")
except Exception as e:
# 3. 捕获其他所有未预见的异常(兜底)
print(f"未知错误:{e}")
else:
# 4. 如果 try 块里没有发生异常,执行这里的代码
print("一切正常,没有错误。")
finally:
# 5. 无论是否发生异常,最后都会执行(通常用于关闭文件或数据库连接)
print("清理工作完毕。")
try:
fh = open("testfile", "w")
fh.write("这是一个测试文件,用于测试异常!!")
except IOError:
print "Error: 没有找到文件或读取文件失败"
else:
print "内容写入文件成功"
fh.close()
except 可以捕获多个异常, 如下:
我们也可以手动触发异常!
语句中 Exception 是异常的类型(例如,NameError)参数标准异常中任一种,args 是自已提供的异常参数。
最后一个参数是可选的(在实践中很少使用),如果存在,是跟踪异常对象。
自定义异常 通过创建一个新的异常类,程序可以命名它们自己的异常。异常应该是典型的继承自Exception类,通过直接或间接的方式。以下为与RuntimeError相关的实例,实例中创建了一个类,基类为RuntimeError,用于在异常触发时输出更多的信息。在try语句块中,用户自定义的异常后执行except块语句,变量 e 是用于创建Networkerror类的实例。
HTTPException
HTTPException 是 FastAPI 提供的一个特殊异常,它能让你精确地告诉前端发生了什么事。你要从 fastapi 模块导入它。它最核心的两个参数是 status_code(状态码)和 detail(详情)。detail 不仅仅可以传字符串,还可以传任何能被转换为 JSON 的对象(比如字典或列表)。
from fastapi import FastAPI, HTTPException
app = FastAPI()
@app.get("/items/{item_id}")
async def read_item(item_id: int):
if item_id == 0:
# 主动抛出 HTTP 异常
raise HTTPException(status_code=400, detail="ID 不能为 0 哦!")
return {"item_id": item_id}
return:意味着函数正常结束,返回一个 200 OK 的响应。raise:意味着“出事了”,立即停止当前函数的执行,跳出逻辑,由 FastAPI 接管并返回指定的错误响应。
自定义响应头
有时候,某些安全验证或协议要求在报错时也带上一些信息(比如 OAuth2 规范),你可以使用 headers 参数:
@app.get("/secure-data")
async def get_secure_data(token: str | None = None):
if not token:
raise HTTPException(
status_code=401,
detail="没有权限访问",
headers={"WWW-Authenticate": "Bearer"},
)
return {"data": "这是秘密内容"}
你会发现 starlette.exceptions 里也有一个 HTTPException。
- FastAPI 的 HTTPException:支持在 detail 里传任何 JSON 数据。
- Starlette 的 HTTPException:只支持字符串。
- 结论:永远优先使用 from fastapi import HTTPException,它是专门为 FastAPI 优化过的。
FastApi 进阶
中间件
中间件是一个函数,它会在每一个请求到达对应函数之前,以及每一个响应返回给客户端之前执行添加一段逻辑
- 请求进来时:保安检查你有没有带工牌(鉴权)、记录你进楼的时间(日志)。
- 响应出去时:保安给你贴个封条(添加自定义响应头)、记录你离开的时间(计算耗时)。
import time
from fastapi import FastAPI, Request
app = FastAPI()
@app.middleware("http")
async def add_process_time_header(request: Request, call_next):
# === 1. 请求到达路径操作前的逻辑 ===
start_time = time.perf_counter()
# === 2. 执行路径操作(传递请求给后面的逻辑) ===
response = await call_next(request)
# === 3. 响应返回客户端前的逻辑 ===
process_time = time.perf_counter() - start_time
# 给响应添加一个自定义头,告诉前端后端处理了多久
response.headers["X-Process-Time"] = str(process_time)
return response
request: 所有的请求信息都在这里。call_next: 一个函数,它接收request作为参数,并返回路径操作生成的response。
顺序执行:如果你有多个中间件,它们的执行顺序是:从下往上运行请求逻辑,从上往下运行响应逻辑(像洋葱一样)。
不要在中间件里写重逻辑:因为它会拖慢你的每一个接口。
异常捕获:如果在中间件里发生了未捕获的错误,FastAPI 可能会直接报 500。
from fastapi import FastAPI
from pydantic import BaseModel
from starlette.responses import HTMLResponse, FileResponse
app = FastAPI()
@app.middleware('http')
async def m1(request, call_next):
print("m1执行前置逻辑")
response = await call_next(request)
print("m1执行后置逻辑")
return response
@app.middleware('http')
async def m2(request, call_next):
print("m2执行前置逻辑")
response = await call_next(request)
print("m2执行后置逻辑")
return response
@app.middleware('http')
async def m3(request, call_next):
print("m3执行前置逻辑")
response = await call_next(request)
print("m3执行后置逻辑")
return response
@app.get('/html', response_class=HTMLResponse)
async def get_html():
return HTMLResponse("<h1>Hello</h1>")
m3执行前置逻辑 m2执行前置逻辑 m1执行前置逻辑 m1执行后置逻辑 m2执行后置逻辑 m3执行后置逻辑
装饰器
在 Python 中,装饰器是一种 “函数包装器”。它的本质是一个函数,接收另一个函数作为参数,并返回一个新的函数,以此来增强或修改原函数的功能。
*args:万能的位置参数 (Positional Arguments) : args 是 arguments 的缩写。前面的 * 告诉 Python:“把所有按顺序传进来的参数,统统打包成一个元组(Tuple)装进 args 里。”
**kwargs:万能的关键字参数 (Keyword Arguments): kwargs 是 keyword arguments 的缩写。前面的 ** 告诉 Python:“把所有带名字的参数(如 a=1),统统打包成一个字典(Dictionary)装进 kwargs 里。”
def my_logger(func):
# wrapper 就像是一个“替身”
# 它必须能接收原函数 func 可能会收到的任何参数
def wrapper(*args, **kwargs):
# 1. 替身先做点事(打印日志)
print(f"日志:{func.__name__} 被调用了")
# 2. 核心:替身把收到的所有参数,“原封不动”地传给真正的函数
# 这里的 * 和 ** 是解包:把口袋里的东西再掏出来按原样摆好
result = func(*args, **kwargs)
# 3. 替身拿到结果,返回出去
return result
return wrapper
依赖注入
SpringBoot 的依赖注入是: 通俗来说,当一个类(比如 UserController)需要用到另一个类(比如 UserService)的功能时, 我们不再自己去 new UserService(),而是只需要声明出来, 然后被动地等待容器(如 Spring)把这个对象“注入”进来即可。
FastApi : “你的函数需要什么,你就声明什么,FastAPI 负责帮你把它取来。”, 逻辑是: 执行依赖函数 -> 拿到结果 A -> 执行接口。
- 减少重复代码:比如每个接口都要检查用户登录,不用每个函数都写一遍逻辑。
- 解耦:业务逻辑和底层资源(如数据库连接)分开。
-
方便测试:可以轻松地把真实的数据库换成测试用的模拟数据库。
-
创建依赖项 (函数)
- 导入 Depends
- 声明依赖项
app = FastAPI()
async def common_parameters(
skip:int = Query(0, ge=0),
limit:int = Query(10, le=100)
):
return {"skip" : skip, "limit" : limit}
@app.get('/')
async def home(common=Depends(common_parameters)):
return common
ORM
from sqlalchemy.ext.asyncio import create_async_engine, async_sessionmaker, AsyncSession
from sqlalchemy.orm import DeclarativeBase
from typing import AsyncGenerator
# 1. 数据库配置(生产环境建议从 .env 加载)
DATABASE_URL = "mysql+aiomysql://root:123456@localhost:3306/news_app?charset=utf8mb4"
# 2. 创建异步引擎
# echo=True 在开发阶段很有用,能看到生成的 SQL,生产环境建议关掉
async_engine = create_async_engine(
DATABASE_URL,
echo=False,
pool_size=10, # 连接池基础连接数
max_overflow=20, # 连接池允许溢出的最大连接数
pool_recycle=3600, # 连接回收时间(防止 MySQL 8小时断连问题)
pool_pre_ping=True # 每次取连接前先“ping”一下,确保连接可用
)
# 3. 创建异步会话工厂
AsyncSessionLocal = async_sessionmaker(
bind=async_engine,
class_=AsyncSession,
expire_on_commit=False, # 异步必备,防止 commit 后无法访问对象属性
autocommit=False,
autoflush=False
)
# 4. 声明 ORM 基类(所有的 Model 都继承这个)
class Base(DeclarativeBase):
pass
# 5. Dependency: 获取数据库会话的通用模板
# 使用 AsyncGenerator 配合 FastAPI 的 Depends 自动管理生命周期
async def get_db() -> AsyncGenerator[AsyncSession, None]:
async with AsyncSessionLocal() as session:
try:
yield session
# 💡 提示:
# 如果你在 Service/CRUD 层已经手动 commit 了,这里重叠 commit 没关系。
# 如果你想实现“整个请求作为一个大事务”,可以在这里统一 commit。
await session.commit()
except Exception:
await session.rollback()
raise
finally:
await session.close()
在 Java 生态里,你的“老伙计”可能是 Hibernate 或 MyBatis。而在 Python/FastAPI 的世界里,虽然有非常多的选择,但最稳、最强、最像 Hibernate 的王者只有一位:SQLAlchemy。
SQLAlchemy 介绍

SQLAlchemy 不仅仅是一个简单的对象映射工具,它在 Python 生态中的地位相当于 Hibernate 之于 Java。它的设计哲学是:数据库不只是表的集合,更是关系代数的引擎。
SQLAichemy 的安装
- 安装 sqlalchemy 以及全异步支持 asyncio
- 安装对于数据库驱动
| 数据库 | 异步驱动 (Driver) | 安装命令 |
|---|---|---|
| PostgreSQL | asyncpg (最推荐) |
pip install asyncpg |
| MySQL | aiomysql |
pip install aiomysql |
| SQLite | aiosqlite |
pip install aiosqlite |
建表
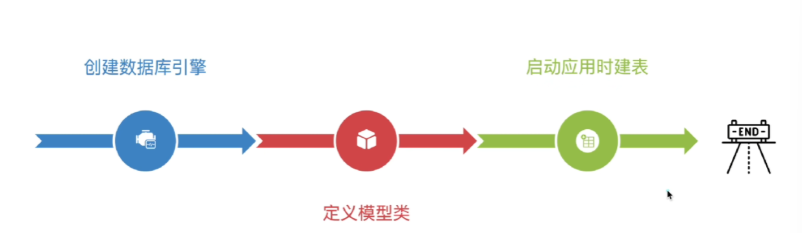
创建数据库引擎
from sqlalchemy.ext.asyncio import create_async_engine, async_sessionmaker, AsyncSession
from sqlalchemy.orm import DeclarativeBase
# 数据库连接 URL (以 SQLite 异步驱动 aiosqlite 为例)
ASYNC_DATABASE_URL = "mysql+aiomysql://root:liuqiang@localhost:3306/fastapi?charset=utf8mb4"
# 创建异步引擎
# echo=True 可以让你在控制台看到执行的 SQL 语句,开发环境建议开启
engine = create_async_engine(DATABASE_URL, echo=True)
# 创建异步会话工厂
AsyncSessionLocal = async_sessionmaker(
bind=engine,
class_=AsyncSession,
expire_on_commit=False
)
from sqlalchemy.orm import Mapped, mapped_column
# 定义基类(所有的模型类都要继承这个 Base)
class Base(DeclarativeBase):
pass
# 定义用户模型类
class User(Base):
__tablename__ = "users" # 数据库中的表名
id: Mapped[int] = mapped_column(primary_key=True, index=True)
username: Mapped[str] = mapped_column(unique=True, index=True)
email: Mapped[str] = mapped_column(nullable=True)
-
启动应用时建表
from fastapi import FastAPI from contextlib import asynccontextmanager @asynccontextmanager async def lifespan(app: FastAPI): # --- 启动时建表逻辑 --- async with engine.begin() as conn: # 这个操作会扫描所有继承了 Base 的类,并在数据库创建不存在的表 await conn.run_sync(Base.metadata.create_all) yield # --- 关闭时逻辑(如果有) --- app = FastAPI(lifespan=lifespan) -
代码执行到
yield时,会暂停。 - 此时,FastAPI 主程序接管控制权,开始处理用户的 HTTP 请求。
- 当你手动关闭服务器(Ctrl+C)时,它会回到
yield之后的位置继续执行。
在 Path Operation Function 中使用 ORM
1. 定义“获取会话”的依赖项 (Repository 准备)
在 Spring 中,你会 @Autowired 一个 Repository。在 FastAPI 中,我们定义一个异步的 get_db 函数作为依赖项。
from sqlalchemy.ext.asyncio import async_sessionmaker, AsyncSession
# 创建异步会话工厂
async_session_factory = async_sessionmaker(
bind=engine,
class_=AsyncSession,
expire_on_commit=False,
)
# 这是一个依赖项函数
async def get_db():
async with async_session_factory() as session:
try:
yield session
await session.commit()
except Exception as e:
await session.rollback()
print("获取会话失败", e)
finally:
await session.close()
2. 在 Handler (函数) 中注入并使用
from fastapi import Depends
from sqlalchemy import select
@app.get("/books/{book_id}")
async def get_book_handler(book_id: int, db: AsyncSession = Depends(get_db)):
"""
这个就是你说的 Handler。
它绑定了 /books/{book_id},专门处理查询书籍的请求。
"""
# 使用 ORM 进行查询
result = await db.execute(select(Book).where(Book.id == book_id))
book = result.scalars().first()
if not book:
return {"msg": "书籍未找到"}
return book
ORM 万能写法, TEXT
当你觉得 ORM 的 select() 语法太绕,或者想写一些极其复杂的、特定于数据库(如 MySQL 特有函数)的查询时,就可以直接写 SQL 字符串。
但是,作为一个 Java 开发者,你一定知道 SQL 注入 的风险。在 SQLAlchemy 中,我们绝对不能用 Python 的 f-string 来拼接参数,而必须使用 绑定参数 (Bound Parameters)。
在 text() 字符串中,参数统一用 :变量名 表示。
from sqlalchemy import text
# 1. 编写带占位符的 SQL
# 注意:冒号后面紧跟变量名,中间不能有空格
sql = text("SELECT * FROM book WHERE author = :author_name AND price > :min_price")
# 2. 执行并传入参数字典
# params 里的 key 必须和 SQL 里的变量名一一对应
result = await db.execute(sql, {"author_name": "鲁迅", "min_price": 50})
# 3. 结果处理
books = result.all() # 注意:原生 SQL 返回的是 Row 对象,不是 ORM 模型实例
ORM 条件查询
- 第一步:用
select(Model)构建“想查什么”。 - 第二步:用
.where(),.limit()链式调用构建“怎么查”。 - 第三步:用
db.execute(stmt)发送给数据库。 - 第四步:用
.scalars().all()或.first()拿到 Python 对象。
核心语法
在 2.0 中,所有的查询都始于 select() 函数。
from sqlalchemy import select
# 相当于: SELECT * FROM book;
stmt = select(Book)
# 执行查询
result = await db.execute(stmt)
# 重点:result 是一个结果集对象,需要调用以下方法获取具体数据
books = result.scalars().all() # 获取所有对象的列表
result.scalars():因为 execute 默认返回的是一行行的数据(类似 Row 对象),
调用 scalars() 可以将其“降维”成你定义的 Book 对象。
可以使用 .where() 来添加过滤条件,这和 SQL 的语法几乎一致。
# 相当于: SELECT * FROM book WHERE id = 1;
stmt = select(Book).where(Book.id == 1)
book = (await db.execute(stmt)).scalar_one_or_none() # 拿到一个结果或返回 None
# 多个条件 (相当于 AND)
stmt = select(Book).where(Book.author == "鲁迅", Book.price > 50)
| 逻辑 | Python 写法 | 生成的 SQL |
|---|---|---|
| 等于 | Book.name == "Java" |
name = 'Java' |
| 不等于 | Book.name != "Java" |
name <> 'Java' |
| 模糊查询 | Book.name.contains("Python")Book.name.like("%Python%") |
name LIKE '%Python%' |
| 包含 | Book.id.in_([1, 2, 3]) |
id IN (1, 2, 3) |
| 排序 | select(Book).order_by(Book.price.desc()) |
ORDER BY price DESC |
| 逻辑与 | Book.xxx == xx & ... |
xxx and xxx |
| 逻辑或 | Book.xxx == xx \| ... |
xxx or xxx |
复杂逻辑(AND, OR, NOT), 如果需要复杂的逻辑组合,需要导入 and_, or_ 函数, 或者直接用 |, &, in_(list)
from sqlalchemy import or_, and_
# 相当于: WHERE (price > 100 OR author == 'Gemini')
stmt = select(Book).where(
or_(Book.price > 100, Book.author == "Gemini")
)
分页
ORM 聚合查询
聚合计算: func.方法(模型类.属性) count, avg, max, min, sum
from sqlalchemy import func
# 相当于: SELECT count(id) FROM book;
stmt = select(func.count(Book.id))
total = (await db.execute(stmt)).scalar()
ORM 新增数据
核心逻辑:实例化模型对象 -> 添加到 Session -> 提交事务。
这里搞清楚 pydantic 下的 BaseModel 和 SQLAichemy 下的 DeclarativeBase 作用不同
前者(BaseModel)用来定义数据的“形状”和“校验规则”,主要负责 API 接口的输入输出(Request/Response)
后者(DeclarativeBase)用来定义数据的“存储结构”,主要负责与数据库表进行映射(ORM)。
- 写法一 : 解包字典
- 写法二: Pydantic 模式 - ✅ 推荐 : 定义一个专门负责接收数据的类(Schema/DTO)。
# 1. 这是 Pydantic 模型,专门负责验证前端传来的 JSON class BookCreate(BaseModel): name: str author: str price: float # 2. 这是 Handler @app.post('/book') async def add_book(book_in: BookCreate, db: AsyncSession = Depends(get_db)): # 核心转换步骤:Pydantic -> SQLAlchemy new_book = Book(**book_in.model_dump()) #⭐⭐ pydantic --> sqlalchemy db.add(new_book) await db.commit() await db.refresh(new_book) # 为了拿到数据库生成的 ID return new_book
ORM 更新数据
更新数据主要有两种流派:“先查再改”流派(最常用、最安全)和 “直接批量更新”流派(最高效)。
方式一 : 先查后改
@app.put("/books/{book_id}")
async def update_book(book_id: int, book_in: BookUpdate, db: AsyncSession = Depends(get_db)):
# 1. 先查询出该对象
result = await db.execute(select(Book).where(Book.id == book_id))
db_book = result.scalar_one_or_none()
if not db_book:
return {"msg": "书籍不存在"}
# 2. 修改属性 (手动或循环)
# update_data = book_in.model_dump(exclude_unset=True)
# exclude_unset=True 的意思是:前端没传的字段就不改,实现“部分更新”
db_book.name = "新书名"
db_book.price = 99.9
# 3. 提交事务
# 注意:这里不需要调用 db.add(),因为 db_book 已经在 session 的监控下了
await db.commit()
await db.refresh(db_book)
return db_book
方法二 : 如果你不想先查一遍(省掉一次 SELECT),或者想一次性更新多条数据,可以使用 update 表达式。
async def bulk_update_price(db: AsyncSession = Depends(get_db), author_name: str):
# 相当于: UPDATE book SET price = price + 10 WHERE author = :author_name
stmt = (
update(Book)
.where(Book.author == author_name)
.values(price=Book.price + 10)
)
await db.execute(stmt)
await db.commit()
部分更新写法
@app.patch("/books/{book_id}") # PATCH 通常用于部分更新
async def patch_book(book_id: int, book_in: BookUpdate, db: AsyncSession = Depends(get_db)):
result = await db.execute(select(Book).where(Book.id == book_id))
db_book = result.scalar_one_or_none()
if db_book:
# 将 Pydantic 接收到的数据转为字典,且只包含用户传了的字段
update_data = book_in.model_dump(exclude_unset=True)
# 像遍历 Map 一样给 ORM 对象赋值 (类似 Java 的反射赋值)
for key, value in update_data.items():
# 如果当前字段为 str 且为空字符串, 不去更新
if isinstance(value, str) and not value.strip():
continue
setattr(db_book, key, value) # 类似与通过java的反射去调用对象的setter方法
await db.commit()
await db.refresh(db_book)
return db_book
ORM 删除数据
方法一 : 先查询,再删除(适合需要前置校验的场景)
@app.delete("/book/{book_id}")
async def delete_book(book_id: int, db: AsyncSession = Depends(get_db)):
# 1. 先捞出来
result = await db.execute(select(Book).where(Book.id == book_id))
db_book = result.scalar_one_or_none()
if not db_book:
return {"msg": "书都不存在,删不了一点"}
# 2. 标记删除
await db.delete(db_book)
# 3. 提交事务
await db.commit()
return {"msg": f"成功火化了 ID 为 {book_id} 的书"}
方法二 : 直接删就完了
@app.delete("/book/{book_id}")
async def quick_delete(book_id: int, db: AsyncSession):
stmt = delete(Book).where(Book.id == book_id)
await db.execute(stmt)
await db.commit()
方法三 : 逻辑删除 (修改) pass
FastApi 实践
FastApi 项目架构
my_fastapi_app/
├── app/
│ ├── __init__.py
│ ├── main.py # 入口文件:初始化 App, 挂载路由
│ ├── config/ # 核心配置:config, 安全设置, 常量
│ │ ├── db_conf.py
│ │ └── security.py
│ ├── models/ # SQLAlchemy ORM 模型 (里子)
│ │ ├── __init__.py
│ │ ├── book.py
│ │ └── user.py
│ ├── schemas/ # Pydantic 模型 (面子/DTO)
│ │ ├── __init__.py
│ │ ├── book.py
│ │ └── user.py
│ ├── crud/ # 逻辑封装:专门存放数据库增删改查函数
│ │ ├── crud_book.py
│ │ └── crud_user.py
| |── utils/ # 工具方法
│ └── api/ # 路由层:相当于 Java 的 Controller
│ ├── v1/
│ │ ├── api.py # 汇总所有路由
│ │ └── endpoints/ # 具体的路由处理
│ │ ├── books.py
│ │ └── users.py
├── tests/ # 测试用例
├── .env # 环境变量 (数据库密码等)
├── alembic/ # 数据库迁移工具配置
└── requirements.txt
📦 Models 层 (SQLAlchemy) : 只定义数据库表结构。
🧪 Schemas 层 (Pydantic) : 定义 Request Body 和 Response Body 的格式。
🛠️ CRUD 层 (业务逻辑封装) : 把具体的 db.execute 等操作封装成函数。
🛣️ API Endpoints 层 (Routers) : 负责解析 HTTP 请求,调用 CRUD 函数,返回响应。
开发流程

模块化路由 APIRouter
模块化路由就是把每个业务功能的接口拆分到独立的文件中, 然后统一挂载到 app, 避免 main.py "爆炸" !
在 app/api/v1/endpoints/books.py 中:
router = APIRouter()
@router.post("/", response_model=BookOut) # 指定返回格式
async def create_book(book_in: BookCreate, db: AsyncSession = Depends(get_db)):
return await crud_book.create(db, obj_in=book_in)
在 app/main.py 中汇总:
跨域问题
只需要导入中间件, 然后配置允许那些不同源的 C 端 访问我们的服务器即可
from fastapi.middleware.cors import CORSMiddleware
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
passlib 密码加密
🛡️bug : passlib 一直说密码长度超过了 72 个字节, 解决无果, 直接用原生 bcrypt
import bcrypt
# 既然 passlib 不行,我们就用原生 bcrypt 手写一个一样的功能
class PwdContext:
def hash(self, password: str) -> str:
# 1. bcrypt 处理的是字节流
password_bytes = password.encode('utf-8')
# 2. 生成盐 (salt)
salt = bcrypt.gensalt()
# 3. 生成哈希
hashed = bcrypt.hashpw(password_bytes, salt)
# 4. 返回字符串格式供数据库存储
return hashed.decode('utf-8')
def verify(self, plain_password: str, hashed_password: str) -> bool:
try:
# 校验时将明文和数据库里的哈希串都转成 bytes 传给 bcrypt
return bcrypt.checkpw(
plain_password.encode('utf-8'),
hashed_password.encode('utf-8')
)
except Exception:
return False
# 实例化对象,这样你原来的调用处都不用改
pwd_context = PwdContext()
def get_hash_pwd(password: str):
return pwd_context.hash(password)
def verify_password(plain_password: str, hashed_password: str):
return pwd_context.verify(plain_password, hashed_password)
封装通用返回结果
java 风格的分装, 你要主要这里的 data 必须是一个能直接序列化的对象, 不能是 orm 对象, 所以传之前建议 data=jsonable_encoder(data)
# 1. 声明一个泛型变量 T# "T" 是字符串名(通常和变量名一致),用于报错时的提示
T = TypeVar("T")
class Result(PydanticBase, Generic[T]):
code: int
message: str
data: T | None = None
model_config = ConfigDict(from_attributes=True)
@classmethod
def build(cls, code: int, message: str, data: T | None = None):
return cls(code=code, message=message, data=data)
@classmethod
def success(cls, data: T | None = None):
return cls(code=200, message="success", data=data)
@classmethod
def error(cls, code: int, message: str):
return cls(code=code, message=message)
黑马讲法:
抽取通用逻辑
def success(message: str='success', data = None):
result = {
"code": 200,
"message": message,
"data": data
}
return JSONResponse(content=jsonable_encoder(result))
编写 pydantic 响应对象
class UserRespBase(BaseModel):
nickname: Optional[str] = Field(None, description="昵称", max_length=50)
gender: Optional[str] = Field(None, description="性别", max_length=10)
bio: Optional[str] = Field(None, description="简介", max_length=500)
avatar: Optional[str] = Field(None, description="头像URL", max_length=255)
class UserResp(UserRespBase):
id: int
username: str
# from_attributes: 告诉 pydantic 如何将 ORM 模型转换为 Pydantic 模型
# populate_by_name=True: 告诉 pydantic 如何将 ORM 模型中的属性名映射到 Pydantic 模型中的属性名
model_config = ConfigDict(
from_attributes=True
)
class UserAuthResp(BaseModel):
token: str
user_info: UserResp = Field(..., description="用户信息", alias="userInfo")
# from_attributes: 告诉 pydantic 如何将 ORM 模型转换为 Pydantic 模型
# populate_by_name=True: 告诉 pydantic 如何将 ORM 模型中的属性名映射到 Pydantic 模型中的属性名
model_config = ConfigDict(
from_attributes=True,
populate_by_name=True
)
通过 UserAuthResp(token = token,user_info = UserResp.model_validate(usr))
来生成响应结果 UserAuthResp
⭐⭐UserResp.model_validate(usr)能快速从 orm 对象生成指定的 pydantic 对象, 注意开始 from_attributes=True
usr = await user.create_user(db, userIn.username, userIn.password)
token = await user.create_token(db, usr.id)
data = UserAuthResp(token = token,user_info = UserResp.model_validate(usr))
return success("注册成功", data)
全局异常处理
核心思想
FastAPI 的异常处理逻辑与 Spring 的 @ExceptionHandler 完全一致。它的本质是在 ASGI 应用实例 (app) 上注册一个“捕获网”,当业务代码抛出特定类型的错误时,app 会自动截获并执行预设的处理函数。
实现步骤
定义自定义业务异常 (Exception Class)
class BusinessException(Exception):
def __init__(self, code: int, message: str):
self.code = code
self.message = message
编写异常处理器 (The Handler)
async def business_exception_handler(request: Request, exc: BusinessException):
# 使用你封装的 Result 统一返回格式
return JSONResponse(
status_code=200, # 业务异常通常也给前端返回 200 状态码
content=jsonable_encoder({
"code": exc.code,
"message": exc.message,
"data": None
})
)
注册到 App (Registration)
from fastapi import FastAPI
app = FastAPI()
# 注册:告诉 app 只要看到 BusinessException,就去跑 b_e_handler
app.add_exception_handler(BusinessException, business_exception_handler)
和 java 一样, 我们可以给一个兜底处理器